데이터 중심 애플리케이션 설계 Ch 5. 복제
# 분산 데이터
여러 장비 간 분산된 DB를 필요로 하는 이유는 여러 가지다.
- 확장성: 데이터 볼륨, 읽기 부하, 쓰기 부하를 분산할 수 있다.
- 내결함성/고가용성: 특정 장비들이 죽더라도 애플리케이션이 계속 동작하도록 할 수 있다.
- 지연 시간: 글로벌 서비스의 경우 지리적으로 가까운 곳의 데이터센터를 이용하여 낮은 지연 시간을 제공할 수 있다.
여러 노드에 데이터를 분산하는 방법은 일반적으로 두 가지가 있다. 이 두가지는 별도의 메커니즘이지만 서로 연관되어 사용된다.
- 복제: 같은 데이터의 복사본을 여러 노드에 유지한다. 데이터가 중복되므로 특정 노드가 죽더라도 중복된 데이터를 보유한 노드를 통해서 데이터를 제공할 수 있다.
- 파티셔닝: 큰 DB를 파티션이라는 작은 서브셋으로 나누고, 각 파티션은 각 다른 노드에 할당한다.(샤딩이라고도 함)
# 복제
데이터 복제가 필요한 이유는 다음과 같다.
- 지리적으로 사용자와 가깝게 데이터를 유지해 지연 시간을 줄인다.
- 일부 노드에 장애가 발생해도 동작할 수 있도록 해 가용성을 높인다.
- 읽기 질의를 제공하는 노드의 수를 확장해 읽기 처리량을 늘린다.
복제 데이터가 시간이 지나도 변경되지 않으면 복제는 쉽지만 복제 데이터는 변경된다. 변경되는 데이터를 노드 간 복제하기 위한 대표적인 알고리즘으로 단일 리더, 다중 리더, 리더 없는복제 방식이 있다.
# 1. 단일 리더 복제
# 리더와 팔로워
DB의 복사본을 저장하는 각 노드를 복제 서버(replica)라고 한다. 모든 복제 서버에 데이터가 복제된 것을 보장하기 위해 일반적으로 리더 기반 복제를 활용한다.
- 복제 서버 중 하나를
리더(마스터, 프라이머리)로 지정하고 클라이언트로부터의 모든 쓰기 요청은 리더에게만 전달된다. - 리더는 자신의 서버에 데이터를 기록하고
팔로워(슬레이브, 세컨더리)복제 서버에 쓰기 요청을 전달한다.- 클라이언트 관점에서 쓰기는 리더만 허용하므로 팔로워는 읽기 전용이다.
- 리더가 팔로워에게 쓰기 내용을 전달할 땐 복제 로그(replication log)나 변경 스트림(change stream)을 주로 활용한다.
- 리더기반 복제 방식은 여러 RDB에 내장되어 있고 카프카 같은 분산 메시지 브로커에서도 사용된다.
# 동기식 복제 vs 비동기식 복제
- 동기식 복제의 장단점
- 장점: 팔로워가 리더와 일관성 있게 최신 데이터 복사본을 가지는 것을 보장한다.
- 단점: 팔로워가 죽거나 네트워크 문제가 있으면 쓰기가 처리될 수 없어 쓰기 가용성이 낮아지고 기본적인 지연 시간도 길어진다.
- 비동기식 복제의 장단점
- 장점: 모든 팔로워가 잘못되더라도 쓰기는 계속 동작 가능하므로 쓰기 가용성이 높다.
- 단점: 팔로워에게 복제가 전달되지 않아 팔로워 측 쓰기가 유실될 수 있다.
- 동기식 복제는 한 노드의 장애가 전체 시스템을 멈추게 하므로 비현실적이다.
- 현실적으로 팔로워 하나만 동기식으로, 나머지는 비동기식으로 복제하는 방식을 사용할 수 있다.
- 이 방식이
반동기식(semi-synchronouse)이라고 한다.
- 이 방식이
- 보통 리더 기반 복제는 팔로워를 지리적으로 분산하여 단점을 보완하고 완전히 비동기식으로 구성된다.
# 새로운 팔로워 추가
- 팔로워가 추가되어 기존 리더의 데이터를 복제할 때 가용성을 위해 중단없이 수행가능해야 한다. 그 과정을 다음과 같다.
- 전체 DB를 잠그지 않고, 리더 DB의 스냅숏 가져온다.
- 스냅숏을 이용하여 새로운 팔로워 노드에 복사한다.
- 팔로워는 리더에게 스냅숏 이후에 발생한 모드 데이터 변경을 요청한다.
- 팔로워가 스냅숏 이후의 미처리분(backlog)을 모두 처리하면 따라잡았다고 말한다.
# 노드 중단 처리
리더 기반 복제에서 팔로워 장애는 쉽게 복구 가능하다.
- 장애난 팔로워가 살아나면 먼저 보관된 로그에서 결함이 발생하기 전에 처리한 트랜잭션을 파악한다.
- 팔로워는 리더에게 연결이 끊어진 동알 발생한 데이터 변경을 요청하여 따라잡는다.
하지만 리더의 장애를 처리하는 건 매우 까다롭다.
- 팔로워 중 하나를 새로운 리더로 승격해야 하고, 클라이언트는 새로운 리더로 쓰기를 전송하기 위해 재설정이 필요하며, 다른 팔로워는 새로운 리더로부터 데이터 변경을 소비하기 시작해야 한다.
- 이러한 과정을
장애 복구(failover)라고 한다.
# 리더 장애 복구 과정
- 리더가 장애인지 판단한다.
- 장애를 판단할 확실한 방법이 없으므로 보통 타임아웃을 사용한다.
- 새로운 리더를 선택한다.
- 보통 선출과정을 통하거나 지정된 제어 노드에 의해 임명된다. 적합한 후보는 기존 리더의 최신 데이터 변경사항을 가진 복제 서버이다.
- 새로운 리더를 사용하기 위해 시스템을 재설정한다.
- 이전 리더가 돌아오면 자신이 리더라도 착각할 수 있으므로 시스템 재설정을 통해 알 수 있도록 해야 한다.
- 이러한 장애 복구 과정은 잘못된 수 있는 것 투성이다.
- 비동기식의 경우 새로운 리더는 기존 리더가 실패하기 전 쓰기의 일부를 수신하지 못할 수 있다.
- 단순히 기존 리더가 복구되었을 때 해당 쓰기를 전파하는건 새로운 리더가 그동안 충돌되는 쓰기를 받았을 수 있으므로 위험하다.
- 기존 리더로 부터 복제되지 않은 데이터를 폐기하는건 클라이언트의 예상에 벗어날 수 있어 클라이언트에서 다른 저장소와 연동을 하고 있다면 위험하다.
- 특정 상황(8장 참고)에 기존 리더와 새로운 리더 모두 자신이 리더라고 믿을 수 있다. 이를
스플릿 브레인이라고 한다.- 데이터가 유실되거나 오염될 수 있으므로 매우 위험한 상황이다.
- 리더가 분명히 죽었다고 판단할 수 있는 적절한 타임아웃을 명확하게 정할 수 없다.
- 타임아웃이 짧으면 리더가 죽지 않았는데 장애 복구가 수행될 수 있고, 너무 길면 복구까지 오랜 시간이 소요된다.
- 비동기식의 경우 새로운 리더는 기존 리더가 실패하기 전 쓰기의 일부를 수신하지 못할 수 있다.
이 문제에 대한 쉬운 해결책은 없기 때문에 소프트웨어가 자동 장애 복구를 지원하더라도 수동으로 장애 복구를 수행하는 방식이 선호되기도 한다.
- 노드 장애, 불안정한 네트워크, 지속성, 가용성, 지연 시간 등의 문제는 분산 시스템에서 발생하는 근본적인 문제로 8, 9장에서 자세히 확인하자.
# 복제 로그 구현
# 구문 기반 복제(statement-based replication)
- 리더는 모든 쓰기 요청을 기록하고 쓰기를 실행한 다음 구문 로그를 팔로워에게 전송한다.
- RDB는 INSERT, UPDATE, DELETE 구문을 팔로워에게 전달하고 각 팔로워는 SQL 구문을 파싱하고 실행한다.
- 이 접근법은 복제가 깨질 수 있는 다양한 사례가 있다.
- NOW()같은 비결정적 함수를 호출하는 경우 복제 서버마다 다른 값을 생성할 수 있다.
- 자동증가 칼럼을 사용하는 구문이나 DB의 데이터에 의존하는 구문은 각 복제 서버에서 정확히 같은 순서로 실행되어야 한다.
- 리더에서 비결정적 함수의 고정 값을 반환하도록하여 문제를 해결할 순 있지만 여러 에지 케이스가 존재하여 지금은 일반적으로 다른 복제 방법을 선호한다.
- MySQL 5.1 이전엔 구문 기반 복제를 사용했다가 비결정성이 있는 경우 로우 기반 복제를 사용하도록 변경되었다.
# 쓰기 전 로그 배송
- 일반적으로 저장소 엔진은 모든 쓰기에 대해 로그를 기록한다.
- LSM 트리 기반 엔진은 로그 자체가 저장소의 주요 부분이 된다.
- B 트리 기반 엔진 또한 모든 변경이 쓰기 전 로그(WAL)에 쓰인다.
- 그러므로 복제를 위해 리더는 디스크에 해당 로그를 기록하는 일 외에도 팔로워에게 네트워크로 해당 로그를 전송하기도 한다.
- 이러한 복제 방식은 PostgreSQL, ORACLE등에서 사용된다.
- 이 방식의 가장 큰 단점은 복제가 저장소 엔진과 밀접하게 결합되어 소프트웨어 버전 변경이 불가능 할 수 있다.
- WAL은 가장 저수준 데이터를 기술하기 때문에 버전 불일치를 허용하지 않을 수 있다.
# 로우 기반 복제(row-based replication)
- 복제 로그를 저장소 엔진 내부와 분리하기 위한 대안 하나는 복제와 저장소 엔진을 위해 다른 로그 형식을 사용하는 것이다.
- 이 같은 종류의 복제 로그를 저장소 엔진의 데이터 표현과 구별하기 위해
논리적 로그(lgical log)라고 부른다.- RDB용 논리적 로그는 대개 로우 단위로 DB 테이블에 쓰기를 기술한 레코드 열이다.
- 논리적 로그를 저장소 엔진 내부와 분리했으므로 하위 호환성을 더 쉽게 유지할 수 있고 다른 버전의 소프트웨어나 저장소 엔진을 실행할 수 있다.
# 트리거 기반 복제
- 위 방법들은 DB 시스템에 의해서만 구현되지만 트리거 방식은 애플리케이션에서 구현될 수 있도록 하여 유연성을 제공한다.
- 트리거는 사용자 정의 애플리케이션 코드를 등록하여 데이터베이스 시스템에서 데이터 변경 시 자동으로 실행되게 해준다.
- 일반적으로 트리거 기반 복제는 다른 방식에 비해 오버헤드가 있지만 유연성 때문에 유용한 매우 유용하다.
# 복제 지연 문제
비동기 복제 방식은 팔로워가 뒤쳐지면 오래된 정보를 볼 가능성이 존재한다. 하지만 이런 불일치는 일시적인 상태에 불과하다.
최종적으로 팔로워는 결국 리더의 데이터와 일치하게 된다. 이를 최종적 일관성(Eventual Consistency)이라고 한다.
- 언젠간 데이터가 일치하겠지만 언제 일치되는지는 명확하지 않다. 지연이 매우크면 문제가 될 수 있다.
- 최종적 일관성으로 인해 복제 지연이 있을 때 발생할 수 있는 사례와 해결 방법을 파악해보자.
# 1) 자신이 쓴 내용 읽기
- 자신이 쓴 내용을 바로 다시 읽기 했을 때 복제 서버엔 쓰기가 반영되지 않아 쓰기 전 데이터를 볼 가능성이 존재한다.
쓰기 후 읽기 일관성(자신의 쓰기 읽기 일관성)은 자신이 갱신한 내용에 대해서는 일관성을 보장한다. 단, 다른 사용자에 대해서는 일관성을 보장하지 않는다.- 구현방법 몇 가지는 다음과 같다.
- 사용자가 수정한 내용은 리더로만 읽게 한다.
- 실제로 무엇이 수정되었는지 파악할 방법이 필요한데 프로필 같은 경우 자신만 수정이 가능하므로 자신의 프로필은 무조건 리더에서 읽게하는 규칙을 정하면 될 것이다.
- 여러 사용자가 편집 가능한 경우라면 마지막 갱신 시간을 기준으로 특정 시간 동안 리더에서 읽기를 수행하도록 할 수 있다.
- 클라이언트는 최근 쓰기 타임스탬프를 알 수 있으므로 이를 활용하여 복제가 되지 않았으면 다른 복제 서버에서 읽기를 처리하게 할 수 있다.
- 사용자가 수정한 내용은 리더로만 읽게 한다.
# 2) 단조 읽기
- 사용자가 시간이 꺼꾸로 흐르는 현상을 목격할 수 있다.
- 복제 서버 A, B 중 A서버에만 동기화가 되어있는 시점에 사용자가 처음엔 A 서버를 통해 데이터를 읽을땐 데이터가 반환되지만 그 다음에 B 서버를 통해 데이터를 읽으면 데이터가 반환되지 않을 것이다.
단조 읽기(monotonic read)는 이런 종류의 이상 현상이 발생하지 않음을 보장한다.- 각 사용자는 항상 동일한 복제 서버에서 수행되게끔 하면 이를 해결할 수 있다.
# 3) 일관된 순서로 읽기
- 데이터가 서로 다른 파티션에 저장되고 파티션 리더가 다를 때 실제 시간상으론 A -> B 순으로 입력되었지만 팔로워들은 B -> A 순으로 복제가 될 가능성이 있다.
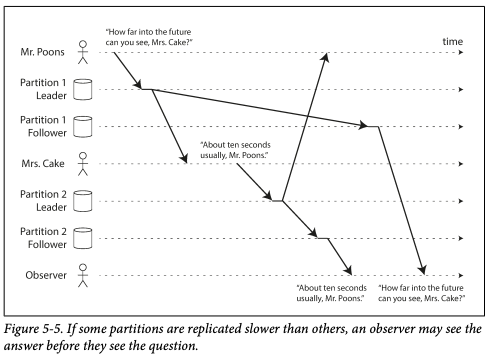
- Observer는 실제로 쓰여진 순서가 아닌 반대로 읽는다.
일관된 순서로 읽기(Consistent Prefix Read)는 이런 종류의 이상 현상이 발생하지 않음을 보장한다.- 특정 순서로 쓰기가 발생하면 이 쓰기를 읽는 모든 사용자는 같은 순서로 쓰여진 내용을 보게 됨을 보장한다.
# 복제 지연을 위한 해결책
- 최종적 일관성으로 인한 복제 지연이 애플리케이션에 얼마나 영향을 끼치는지 파악할 필요가 있다.
- 지연에 대한 영향이 크다면 강력한 일관성을 보장할 수 있도록 시스템을 설계해야 한다.
- 앞에서 설명된 방식으로 애플리케이션에서 강력한 보장을 제공할 수도 있지만 애플리케이션에서 다루기엔 복잡하다.
- 트랜잭션은 이러한 문제에 대한 해결을 데이터베이스 단에서 보장해주지만 분산 데이터베이스로 전환되면서 많은 시스템이 트랜잭션을 포기했다.
- 트랜잭션이 성능과 가용성 측면에서 너무 비싸고, 확장 가능한 시스템에서는 어쩔 수 없이 최종적 일관성을 사용해야한다는 주장이 존재.
# 2. 다중 리더 복제
단일 리더 방식은 리더가 단일장애점이 된다. 가용성을 위해 노드를 하나 이상 두는 것은 합리적이며 이를 다중 리더 설정이라고 부른다.
- 다중 리더 설정에서 각 리더는 동시에 팔로워도 된다.
단일 데이터센터 내에 다중 리더 설정은 복잡도에 비해 이점이 크지 않고 다른 몇몇 상황에서 합리적인 방식이다.
# 1) 다중 데이터센터 운영
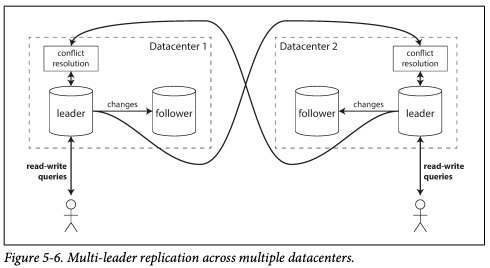
- 다중 데이터센터에서 각 데이터센터마다 리더가 존재하는 방식으로 다중 리더를 세팅할 수 있다.
- DC간의 복제는 리더들간에 이루어지도록 하고 팔로워는 같은 DC의 리더에 의해서만 복제되도록 한다.
- 특징은 다음과 같다.
- 로컬 DC 복제만 동기식으로 하고 DC간 복제는 비동기식으로 해서 성능을 향상 시킬 수 있다.
- 각 DC는 독립적이기 때문에 한 DC 중단에 다른 DC가 영향을 받지 않아 데이터센터 중단 내성을 가진다.
- DC간의 통신은 인터넷을 통하므로 네트워크 문제에 민감하다. 다중 리더는 DC간의 복제는 비동기식이므로 일시적인 네트워크 문제에 내성을 가진다.
- 다중 리더 복제는 이점도 존재하지만 각 리더에 쓰기 충돌이 발생할 수 있다.
# 2) 오프라인 작업을 하는 클라이언트
- 오프라인으로도 애플리케이션이 동작될 수 있는 경우에도 다중 리더 방식이 사용될 수 있다.
- 캘린더같은 앱은 인터넷이 연결되어 있지 않아도 언제든지 캘린더 정보를 볼 수 있고 저장할 수 있다.
- 모든 디바이스는 리더처럼 동작하는 로컬 데이터베이스로 볼 수 있다.
- 디바이스의 인터넷이 연결되면 로컬에 변경된 데이터가 복제 서버로 동기화 된다.
- 아키텍처 관점에서 보면 이 설정은 근본적으로 데이터 센터 간 다중 리더 복제와 동일하다.
# 쓰기 충돌 다루기
- 다중 리더 복제의 가장 큰 문제는 쓰기 충돌이다. 이를 위해 충돌 해소가 필요하다.
- 각 사용자의 변경이 로컬 리더에 정상 적용되고 동기화될 때 충돌이 발생할 수 있다.
- 충돌을 처리하는 가장 단순한 방법은 충돌을 피하는 것이다. 충돌 해소는 어렵기 때문에 자주 사용되는 방식이다.
- 같은 레코드의 쓰기는 동일한 리더를 거치도록 애플리케이션이 보장된다면 충돌은 발생하지 않을 것이다.
- 각 쓰기에 고유 ID를 두고 가장 높은 ID를 가진 쓰기를 고르고 나머지는 버리는 방식을 사용할 수 있다. ID가 타임스탬프라면 최종 쓰기 승리(Last Write Wins)라고 부른다.
- 어떻게든 값을 병합하도록 하여 충돌을 해결할 수도 있다.(텍스트를 사전 순으로 정렬하여 병합한다.)
- 충돌을 모두 기록해 나중에 사용자를 통해 충돌을 해결하도록 한다.
# 다중 리더 복제 토폴로지
복제 토폴로지는 쓰기를 한 노드에서 다른 노드로 전달하는 통신 경로를 말한다.- 리더가 두개라면 다중 데이터센터 운영 구조처럼만 사용할 수 있지만 리더가 둘 이상이라면 다양한 토폴로지가 가능하다.
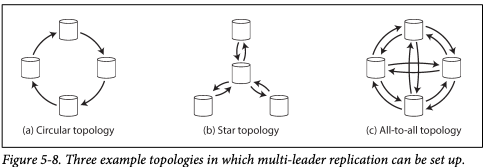
- 원형 토폴로지는 각 노드가 하나의 노드로부터 쓰기를 받고, 이 쓰기를 다른 한 노드에게만 전달한다.
- MySQL에서 기본적으로 이 방식을 사용한다.
- 별 모양 토폴로지는 지정된 루트 노드 하나가 다른 모든 노드에 쓰기를 전달한다. 트리로 일반화된다.
- 전체 연결 토폴로지는 모든 리더가 각자의 쓰기를 다른 모든 리더에게 전송한다.
- 원형과 별 모양 토폴로지는 하나의 노드에 장애가 다른 노드 간 복제 흐름의 방해를 주기 때문에 내결함성이 좋지 않다.
- 전체 연결 토폴로지는 단일 장애점을 피할 수 있어 내결함성이 훨씬 더 좋다.
- 다만 리더간의 네트워크 연결 속도가 다르다면 전체 연결 토폴로지는 일부 복제 데이터가 다른 데이터를 추월하여 일관된 순서로 데이터가 복제되지 않을 수 있다.
# 3. 리더 없는 복제
일부 데이터 저장소 시스템은 리더의 개념을 버리고 모든 복제 서버가 클라이언트로부터 쓰기를 직접 받을 수 있게 허용하는 접근 방식을 사용하기도 한다.
리더 없는 복제는 아마존이 내부 다이나모 시스템에서 사용한 후 다시 데이터베이스 아키텍처로 유행했다.
리악, 카산드라, 볼드모트는 다이나모에서 영감을 얻은 리더 없는 복제 모델의 오픈소스 데이터스토어이며 이런 종류의 데이터베이스를 다이나모 스타일이라고 부른다.
# 읽기 복구와 안티 엔트로피
- 복제는 최종적으로 모든 복제 서버에 복사됨을 보장해야 한다. 다이나모 스타일은 누락된 쓰기 처리를 위해 두 가지 메커니즘을 주로 사용한다.
- 읽기 복구
- 여러 노드에서 병렬로 읽기를 수행하면 오래된 데이터를 포함했는지 감지할 수 있다. 오래된 데이터가 감지되면 복구를 수행한다.
- 안티 엔트로피 처리
- 백그라운드 프로세스를 두어 복제 서버 간 데이터 차이를 지속적으로 찾아 누락된 데이터를 하나의 복제 서버에서 다른 서버로 복사한다.
- 읽기 복구만 사용하는 경우 값을 읽을 때만 복구가 가능하므로 읽지 않는 값은 일부 복제본에 누락될 가능성이 존재한다.
# 읽기와 쓰기를 위한 정족수
- n개의 복제 서버가 있을 때 w개의 노드에 쓰기 성공이 보장되고 읽기는 r개 노드로 수행되는 경우에
w + r > n의 경우 항상 최신 값을 읽는 것을 기대한다.- 정족수(Quorum) 읽기와 쓰기인 경우 위 식을 보장한다. 정족수는 round((n+1)/2)이므로 n=3인 경우 2가 된다.
- 이러한 파라미터를 대개 설정가능하며 쓰기 부하가 많은 경우
r=n, w=1로 설정하고 읽기 부하가 많은 경우w=n, r=1로 설정하여 성능을 높일 수 있다.- 단, 읽기나 쓰기가 n인 경우 하나의 노드만 다운되어도 실패하므로 가용성이 떨어진다.
# 정족수 일관성의 한계
- 모든 읽기가 항상 최신값을 반환함을 보장하는 경우 흔히
Strong Consistency(강력한 일광성)을 보장한다고 한다. - 보통
w + r > n인 경우 강력한 일관성이 보장된다고 하지만 정족수 읽기와 쓰기인 경우 강력한 일관성을 보장하지 않는 에지 케이스가 존재한다.- 쓰기와 읽기가 동시에 발생하는 경우 일부 복제 서버에만 반영이 되어있을 수도 있다. 이 경우 정족수 읽기는 최신 값을 반환하지 않을 수 있다.
- 두 개의 쓰기가 동시에 일어난다면 어떤 쓰기가 먼저 일어났는지 분명하지 않다.
- 쓰기가 일부 복제 서버에 성공했으나
w수를 만족하지 못해도 성공한 서버는 롤백하지 않는다. 클라이언트에게 쓰기가 실패했다고 보고되어도 이어지는 읽기에 새로 쓰인 값이 반환될 수도 있다.
# 최신성 모니터링
- 리더 기반 복제의 경우 팔로워의 복제 지연량을 리더를 통해 쉽게 파악할 수 있지만 리더 없는 복제의 경우 간단하지 않다.
- (아직 모니터링에 대한 표준 모범 사례가 없는 것 같고 읽기 복구와 안티 엔트로피 처리에 의존하는 것으로 보인다.?)
- 최종적 일관성은 의도적을 모호한 보장이지만 운용성을 위해서는
최종적을 정량화할 수 있어야 한다.
# 느슨한 정족수와 암시된 핸드오프
- 노드가 n개 이상인 대규모 클러스터에서 특정 값을 위한 정족수가 충족되지 못하더라도 n에 포함되지 않은 다른 노드에 우선적으로 쓰기를 기록하는 방식을
느슨한 정족수라고 부른다.- A, B, C, D 노드가 존재할 때 특정 값에 대한 복제 노드는 A, B, C(n=3)라고 하자. 이 경우 정족수는 2가 된다.
- 그런데 A, B 노드가 갑자기 다운되어 특정 값을 C노드에만 쓸 수 있는 경우 정족수를 충족시키지 못하므로 실패해야 한다.
- 여기서 n에 속하지 않은 D노드에 해당 쓰기를 임시적으로 수용하도록하고 B, C노드가 복구되면 해당 쓰기를 B, C노드로 전송하도록 한다.
- 이러한 방식을
암시된 핸드오프라고 부른다.
- 느슨한 정족수는 쓰기 가용성을 높이는데 유용하지만 w + r > n인 경우에도 강력한 일관성을 보장하지 않는다.
- 느스한 정족수는 선택 사항으로 리악에서는 기본적으로 활성화되어 있고 카산드라와 볼드모트는 비활성화되어 있다.
# 동시 쓰기 감지
- 다이나모 스타일 데이터베이스는 여러 클라이언트가 동시에 같은 키에 쓰는 것을 허용하므로 쓰기 충돌이 발생한다.
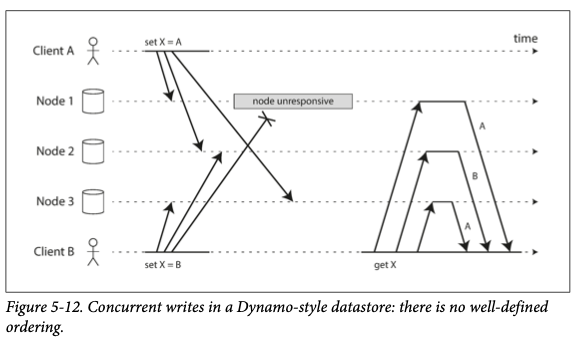
- 동시 쓰기가 발생했을 때 네트워크 지연이나 부분적인 장애로 인해 쓰기 요청이 다른 노드에 다른 순서로 도착하여 위와 같이 일관성이 깨질 수 있다.
- 최종적 일관성을 보장하기 위해선 복제본 값이 동일해야 한다. 어떻게 이를 처리하는지 알아본다.
# 최종 쓰기 승리(LWW)
- 예전 값은 버리고 최신 값으로 덮어쓰는 방법이다. 어떤 쓰기가
최신인지 명확하게 결정할 수 있다면 최종적 일관성이 보장된다. - 하지만
최신을 결정하는건 쉽지 않다. 클라이언트간의 이벤트 순서를 명확하게 알 수 있는 방법이 없다. - 카산드라의 경우 타임스탬프를 기반으로 최신 기준을 정해 예전 타임스탬프를 가진 쓰기는 무시된다.
- 최종 쓰기 승리는 카산드라에서 유일하게 제공하는 충돌 해소 방법이며 리악에서는 선택적 기능이다.
- 이 방식은 동시에 여러번이 쓰기가 있다하더라도 모든 클라이언트는 성공으로 응답을 받지만 결국 최종적으로 하나만 쓰고 나머지는 무시되므로 지속성이 희생된다.
- LWW로 데이터베이스를 안전하게 사용하는 유일한 방법은 키를 한번만 쓰고 이후에는 불변 값으로 다루는 것이다.
- 카산드라의 경우 키로 UUID를 사용해 모든 쓰기가 고유할 수 있도록 하는 방법이 추천된다.
# 동시에 쓴 값 병합
- 서버는 모든 키에 대해 버전을 기록하고 클라이언트가 키를 읽을 때 최신 버전뿐만 아니라 덮어쓰지 않은 모든 값을 병합하여 반환한다.
- 이 경우 삭제를 지원하기 위해서는 단순히 데이터베이스에서 데이터를 삭제하면 안되고 버전 값들을 병합할 때 상품이 제거되었음을 알 수 있는 표시를 남겨둬야 한다. 이런 삭제 표시를
툼스톤이라고 한다.
# 정리
# 복제의 용도
고가용성: 몇몇 장비가 다운되어도 시스템이 계속 동작하게 한다.
네트워크 중단 내성: 네트워크 중단이 있을 때도 애플리케이션이 계속 동작할 수 있게 한다.
지연 시간: 지리적으로 클라이언트와 가까이에 데이터를 배치해 지연 시간을 줄인다.
확장성: 복제본에서 읽기를 수행해 단일 장비에서 다룰 수 있는 양보다 더 많은 읽기 작업을 가능하게 한다.
# 복제 접근 방식
단일 리더 복제: 모든 쓰기를 단일 리더가 수행하고 리더는 데이터 변경 이벤트 스트림을 팔로워에게 전송한다. 읽기는 모든 서버에서 수행가능하나 복제 지연이 발생할 수 있다.
- 단일 리더 복제는 이해하기 쉽고 충돌 해소에 대한 우려가 없어 널리 사용된다.
다중 리더 복제: 여러 리더를 통해 쓰기가 수행될 수 있고 각 리더는 데이터 변경 이벤트 스트림을 다른 리더와 팔로워에게 전송한다.
리더 없는 복제: 모든 노드를 통해 쓰기가 수행될 수 있고 일관성을 위해 병렬로 노드를 읽을 수 있다.
- 다중 리더 복제와 리더 없는 복제는 결함 노드, 네트워크 중단, 지연 시간 급증에 상황에서 더욱 견고하다. 하지만 설명하기 어렵고 일관성이 잘 보장되지 않는다는 단점이 있다.
# 복제 지연 이상 현상
쓰기 후 읽기 일관성: 사용자는 자신이 제출한 데이터를 항상 볼 수 있어야 한다.
단조 읽기: 사용자가 어떤 시점에 데이터를 본 후에는 해당 데이터의 예전 시점의 데이터는 볼 수 없다.
일관된 순서로 읽기: 사용자는 인과성이 있는 상태의 데이터를 봐야 한다.