데이터 중심 애플리케이션 설계 Ch 7. 트랜잭션
트랜잭션은 애플리케이션에서 몇 개의 읽기와 쓰기를 하나의 논리적 단위로 묶는 방법이다.
트랜잭션을 쓰면 애플리케이션에서 오류 처리를 하기가 훨씬 단순해진다. 어떤 연산은 성공하고 어떤 연산은 실패하는 경우처럼 부분적인 실패를 걱정할 필요가 없기 때문이다.
# ACID
트랜잭션이 제공하는 안전성 보장은 흔히 원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability) 을 위미하는 약어인 ACID로 잘 알려져 있다.
# 원자성(Atomicity)
여러 쓰기 작업이 하나의 원자적인 트랜잭션으로 묶이고 트랜잭션은 완료(커밋)되거나 결함 발생 시 해당 트랜잭션의 모든 쓰기 작업이중단(어보트)되거나 둘 중 하나여야 한다.
오류가 생겼을 때 트랜잭션을 어보트하고 해당 트랜잭션에서 기록한 모든 내용을 취소하는 능력이 ACID의 원자성의 결정적인 특성이다.
# 일관성(Consistency)
일관성이라는 단어는 여러 의미로 사용된다.
- eventual/strong consistency에서는 복제 시스템간의 데이터 동기화에 대한 것이다.
- consistent hashing(일관성 해싱)에서는 시스템들의 재균형화를 위한 파티셔닝 방법이다.
- CAP 정리에서의 Consistency는 선형성(strong consistency)을 의미한다.(ch9 참고 (opens new window))
- ACID에서의 Consistency는 트랜잭션이 완료될 때 데이터에 관한
불변식이 반드시 만족되어야 하는 특성을 의미한다.
ACID에서의 일관성은 애플리케이션의 불변식 개념에 의존하고, 일관성을 유지하도록 트랜잭션을 올바르게 정의하는 것은 애플리케이션의 책임이다.
- 유일성 조건 및 외래 키 조건과 같이 데이터베이스에서 확인할 수 있는 불변식이 존재하긴 하지만 이외의 불변식은 애플리케이션에서 정의하며 이 불변식을 데이터베이스에서 검증할 수 없다.
- ACID에서 일관성만 유일하게 애플리케이션의 속성이다. 나머지는 모두 데이터베이스 속성이다.
# 격리성(Isolation)
동시에 실행되는 트랜잭션은 서로 격리되어야 한다. 트랜잭션은 다른 트랜잭션을 방해할 수 없다.
# 지속성(Durability)
트랜잭션이 성공적으로 커밋됐다면 하드웨어 결함이 발생하거나 데이터베이스가 죽더라도 트랜잭션에서 기록한 모든 데이터는 손실되지 않고 지속되어야 한다.
- 지속성을 보장하기 위해서 데이터베이스는 트랜잭션이 성공적으로 커밋됐다고 보고하기 전에 쓰기나 복제가 완료될 때까지 기다려야 한다.
- 완벽한 지속성은 보장할 수 없다. 모든 하드디스크와 백업이 동시에 파괴되면 데이터베이스가 해줄 수 있는건 없다.
# 다중 객체 연산(트랜잭션)
다중 객체 연산을 위해서는 읽기 및 쓰기 연산들이 동일한 트랜잭션에 속하는지 알아야하고 이를 위해 관계형 데이터베이스에서는 TCP 연결 기반으로 BEGIN TRANSACTION문, COMMIT문 등을 통해 확인한다.
반면 비관계형 데이터베이스는 구현의 복잡성과 매우 높은 가용성 및 성능을 위해 이런 방식을 지원하지 않는 경우가 많다.
# 다중 객체 트랜잭션의 필요성
- 단일 객체 트랜잭션 만으로 충분한 사용 사례가 있지만 많은 경우에 다중 객체 트랜잭션이 필요하다.
- 서로 참조하는 여러 레코드를 삽입할 때 참조 키는 항상 올바르고 최신 정보를 반영해야 한다.
- 비정규화된 여러 테이블의 데이터들을 한 번에 갱신해야 한다.
- 보조 색인이 있는 경우 값이 변경될 때 색인도 함께 갱신되어야 한다.
# 오류와 어보트 처리
트랜잭션의 핵심 기능은 오류가 생기면 어보트되고 안전하게 재시도할 수 있다는 것이다.
어보트된 트랜잭션을 재시도하는 것은 간단하고 효과적인 오류 처리 메커니즘이지만 완벽하지 않다.
- 트랜잭션이 실제론 커밋되었지만 네트워크 문제로 클라이언트는 실패했다고 생각하여 중복 처리가 될 수 있다.
- 오류가 과부하 때문이라면 재시도는 더 큰 문제를 만들 수 있다.
- 일시적인 오류(데드락, 네트워크 오류, 시스템 장애)에만 가치있고 영구적인 오류(제약 조건 위반)는 재시도해도 소용이 없다.
# 완화된 격리 수준(Weak Isolation Level)
트랜잭션이 직렬적으로 실행되는 직렬성 격리는 성능 비용이 크기 때문에 많은 데이터베이스는 그 비용을 지불하려고 하지 않는다. 따라서 완화된 격리 수준을 사용하는 시스템들이 흔하다.
완화된 격리 수준은 어떤 동시성 이슈로부터는 보호해주지만 모든 이슈로부터 보호해주지는 않는다. 각 수준별 특성을 파악하여 애플리케이션에 적합한 격리 수준을 선택할 수 있게 하자.
# 커밋 후 읽기(read committed)
가장 기본적인 트랜잭션 격리 수준으로 다음 두 가지를 보장해준다.
- 데이터베이스에서 읽을 때 커밋된 데이터만 본다.(
더티 읽기가 없음) - 데이터베이스에 쓸 때 커밋된 데이터만 덮어쓰게 된다.(
더티 쓰기가 없음)
# 더티 읽기 방지
- 다른 트랜잭션에서 커밋되지 않은 데이터를 보는 경우를
더티 읽기라고 부른다. - 커밋 후 읽기 격리 수준에서는 더티 읽기를 막아야 한다.
- 더티 읽기를 막는게 유용한 이유는 다음과 같다.
- 트랜잭션이 여러 객체를 갱신하는데 더티 읽기가 생기면 일부는 갱신된 값을, 일부는 갱신되지 않은 값을 볼 수 있게 된다.
- 트랜잭션이 어보트되면 롤백해야 하는데 더티 읽기가 생기면 실제로 커밋되지 않은 롤백된 데이터를 볼 수 있게 된다.
# 더티 쓰기 방지
- 아직 커밋되지 않은 트랜잭션에서 쓴 데이터를 새로운 트랜잭션이 덮어 쓰는 경우를
더티 쓰기라고 한다.- 보통 먼저 쓴 트랜잭션이 커밋되거나 어보트될 때까지 두번째 쓰기를 지연시킨다.
- 커밋 후 읽기 격리 수준에서는 더티 쓰기를 막아야 한다.
- 더티 쓰기를 막지 않으면 트랜잭션이 여러 객체를 갱신할 때 갱신 값들이 다른 트랜잭션과 뒤섞여 데이터에 문제가 발생할 수 있다.
# 커밋 후 읽기 구현
- 더티 쓰기의 경우 가장 흔한 방법으로 로우 수준 잠금을 사용해 방지한다.
- 트랜잭션에서 로우(객체)를 변경하고 싶다면 잠금을 획득해야 하고 오직 한 트랜잭션만 어떤 주어진 객체에 대해 잠금을 보유할 수 있다.
- 더티 읽기는 잠금을 사용하면 응답 시간에 많은 영향을 주기 때문에 데이터베이스는 모든 객체에 대해 과거에 커밋된 값과 현재 트랜잭션에서 쓴 새로운 값을 모두 기억한다.
- 다른 트랜잭션은 현재 트랜잭션에서 커밋하기 전 까지는 과거에 커밋된 값을 읽게 된다.
# 커밋 후 읽기 에서는 막을 수 없는 비반복 읽기(non-repeatable read)
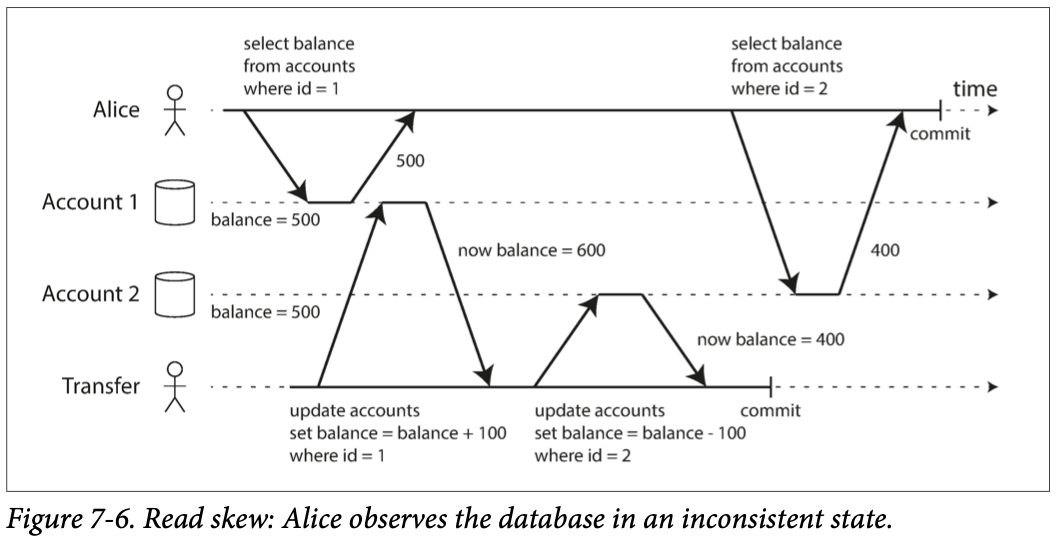
- Account1, 2에 각각 500원 씩 있고 Account2 -> Account1로 100원을 송금(Transfer) 트랜잭션이 수행 중일 때 Alice가 계좌를 확인하는 트랜잭션을 수행하면 비반복 읽기가 발생할 수 있다.
- 계좌 잔고를 확인하는 트랜잭션 내에서 Account1은 송금 트랜잭션 커밋전에 조회하여 500원을 얻고 Account2는 송금 트랜잭션이 커밋된 이후에 조회하여 400원을 얻어 100원이 사라져 버린것 처럼 보일 수 있다.
Read commited는 다른 트랜잭션이 커밋한 데이터를 읽을 수 있기 때문에 한 트랜잭션에서 같은 데이터를 조회할 때 데이터가 달라질 수 있는 것이다. 이런 현상을Non-repeatable read,Read skew라고 한다.
# 스냅숏 격리(Snapshot Isolation)
스냅숏 격리는 비반복 읽기와 같은 문제를 해결할 수 있는 가장 흔한 해결책이다. 트랜잭션은 특정 시점에 고정된 데이터베이스의 일관된 스냅숏만을 볼 수 있다.
각 트랜잭션은 데이터베이스의 일관된 스냅숏으로 부터 읽는다. 그러므로 트랜잭션은 시작할 때 데이터베이스에 커밋된 상태였던 데이터만을 보게 되어 Non-repeatable read가 발생하지 않는다.
스냅숏 격리는 PostgreSQL, InnoDB 엔진 기반의 MySQL, Oracle 등에서 지원한다.
# 스냅숏 격리 구현
- 스냅숏 격리를 구현하기 위해서는 객체마다 커밋된 버전 여러 개를 유지할 수 있어야 한다.
- 데이터베이스가 객체의 여러 버전을 함께 유지하는 기법을 다중 버전 동시성 제어(multi-version concurreny control, MVCC)라고 한다.
- 스냅숏 격리를 지원하는 저장소 엔진은 보통 커밋 후 읽기 격리를 위해서도 MVCC를 사용한다.(커밋된 버전과 아직 커밋되지 않은 버전 2가지로 커밋 후 읽기 격리를 구현할 수 있다.)
- 트랜잭션 별로 고유한 트랜잭션 ID를 할당받고 트랜잭션이 데이터를 쓸 때 마다 해당 트랜잭션 ID와 버전별 객체가 기록되어 트랜잭션에 따라 특정 버전의 객체들을 읽을 수 있도록 한다.
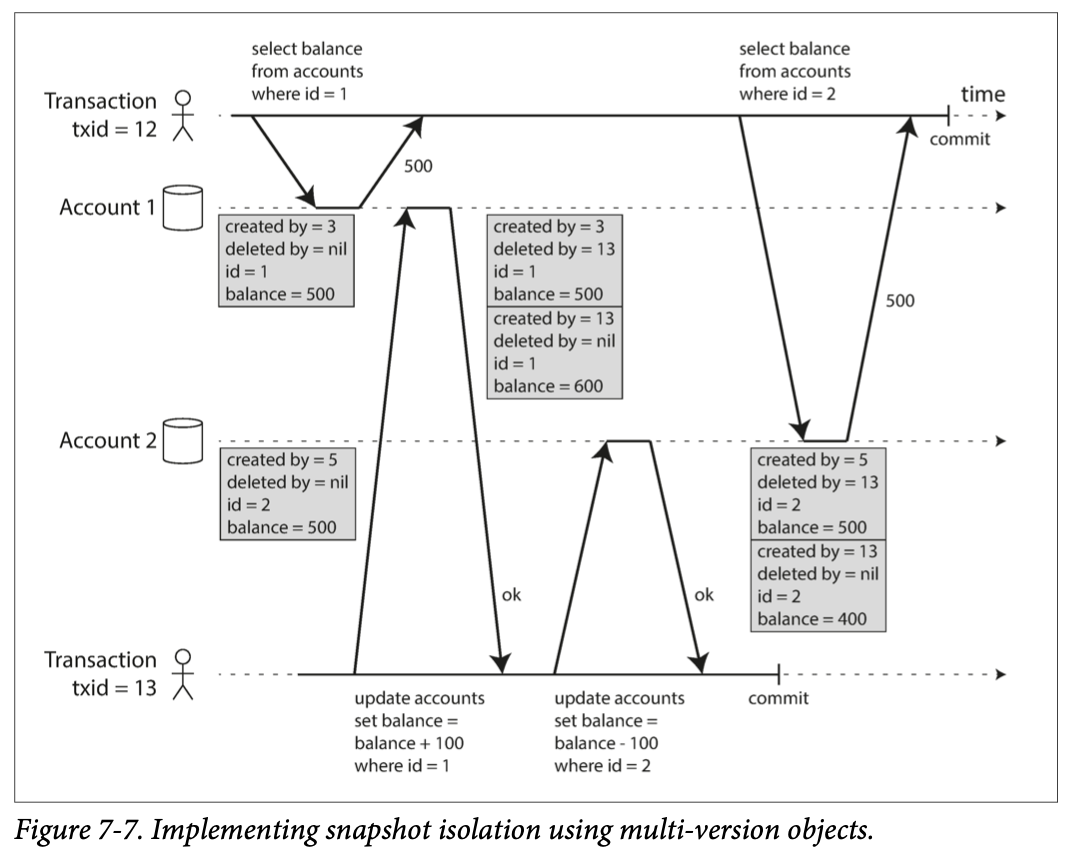
- MVCC 기반의 스냅숏 격리를 통해 이전 예제에서 발생한 비반복 읽기 문제를 해결할 수 있다.
- 트랜잭션이 시작하면 계속 증가하는 고유한 트랜잭션 ID를 할당받고 트랜잭션이 데이터를 쓸 때마다 해당 트랜잭션의 ID를 추가한다.
creatd by,deleted by필드가 있고 각각 필드에 트랜잭션 ID가 설정된다. 가장 최신의deleted by에는 값이 비어있게 된다.- 실제 로우를 수정/삭제하면 데이터베이스에서 지우지 않고
deleted by필드를 설정하여 지워졌다고 표시한다.
- 한 트랜잭션은 자신의 트랜잭션 ID를 기반으로 트랜잭션이 시잘할 때 커밋된 데이터만을 볼 수 있다.
- 삭제된 데이터에 접근하는 트랜잭션이 더 이상 존재하지 않는게 확실해지면 삭제 표시된 로우들을 삭제할 수 있다.
# 반복 읽기(repeatable read) = 스냅숏 격리
- PostgreSQL, MySQL에서는 스냅숏 격리를 반복 읽기라고 한다.
# 갱신 손실(Lost Update) 방지
커밋 후 읽기와 스냅숏 격리는 주로 동시에 실행되는 쓰기 작업에서 읽기 전용 트랜잭션이 무엇을 볼 수 있는지에 대한 보장과 관련된 것이다.
하지만 동시에 실행되는 쓰기 트랜잭션 사이에 발생할 수 있는 충돌 상황들이 존재하며 가장 유명한 것이 갱신 손실(lost update) 문제이다.
- 갱신 손실 문제는 값을 읽고 변경한 후 변경된 값을 다시 써야할 때(read-modify-write) 여러 트랜잭션이 동시에 해당 작업은 수행하는 경우 발생할 수 있다.
- 이 문제는 흔해서 다양한 해결책이 개발되었다.
# 1) 원자적 쓰기 연산
- 여러 데이터베이스에서 원자적 쓰기 연산을 제공하기 때문에 애플리케이션에서 read-modify-write 주기를 구현할 필요를 없애 준다.
UPDATE counters SET value = value + 1 WHERE key = 'foo'이 쿼리는 대부분의 관계형 데이터베이스에서 동시성 안전하다.
# 2) 명시적인 잠금
- 데이터베이스에서 원자적 쓰기 연산을 제공하지 않는다면 애플리케이션에서 객체를 명시적으로 잠그는 방식으로 해결할 수 있다.
- MySQL의 경우 SELECT 시
FOR UPDATE절을 활용하여 로우를 잠글 수 있다. 단, 명시적인 잠금 방식은 실수할 여지가 많다.
# 3) 갱신 손실 자동 감지
- 병렬 실행을 허용하도록 하고 갱신 손실을 자동 감지하여 발견 시 트랜잭션을 어보트 시키고 read-modify-write 주기를 재시도 하도록 강제하는 방법이 있다.
- 이 기능은 명시적인 잠금을 실수로 빼먹었을 때 자동으로 갱신 손실을 감지하여 트랜잭션을 어보트 시킬 수 있기 때문에 유용하다.
- 오라클, SQL 서버는 이 기능을 제공하지만 InnoDB 기반의 MySQL은 이 기능을 제공하지 않는다.
# 4) Compare-and-set
- 트랜잭션을 제공하지 않는 데이터베이스 중에는 원자적
compare-and-set연산을 제공한다. - 이 연산을 통해 값을 읽은 후로 변경되지 않았을 때만 갱신을 허용하여 갱신 손실을 회피할 수 있다.
- 동시에 같은 데이터를 수정할 때
compare-and-set을 활용하면 하나의 갱신 요청만 성공하고 다른 요청은 적용되지 않을 것이다.UPDATE item SET name = 'new name 1' WHERE id = 123 AND name = 'old name'UPDATE item SET name = 'new name 2' WHERE id = 123 AND name = 'old name'- 두 요청이 동시에 들어오면 하나만 성공할 것이고 다른 하나는
WHERE조건이 맞지 않으므로 실패한다. - 만약
WHERE절이 최신 데이터를 읽지 못한다면 갱신 손실을 막지 못할 수도 있다.
# 5) 충돌 해소와 복제
- 다중 리더 복제나 리더 없는 복제를 사용하는 데이터베이스는 여러 노드에 데이터 복사본이 있고 다른 노드에서 동시에 데이터 변경이 가능하므로 갱신 손실 방지를 위해 추가 단계가 필요하다.
- 카운터 증가와 같이 교환 법칙(연산의 순서가 달라져도 상관 없는)이 성립하는 원자적 연산은 복제 상황에서도 잘 동작할 수 있다.
- 많은 데이터베이스에서 채택한
최종 쓰기 승리(Last Wrie Wins)방식을 갱신 손실이 발생하기 쉽다. (ch5 참고 (opens new window))
# 쓰기 스큐(write skew)와 팬텀
쓰기 스큐는 동시에 실행되는 두 트랜잭션이 같은 객체들을 읽어서 그중 일부를 갱신하는데 각각 다른 객체들을 갱신하여 애플리케이션의 요구사항을 위반하게 되는 현상이다.
- 하나의 동일한 객체를 갱신하는 경우에는
더티 쓰기,갱신 손실현상을 겪을 수 있다.
# 쓰기 스큐 예시
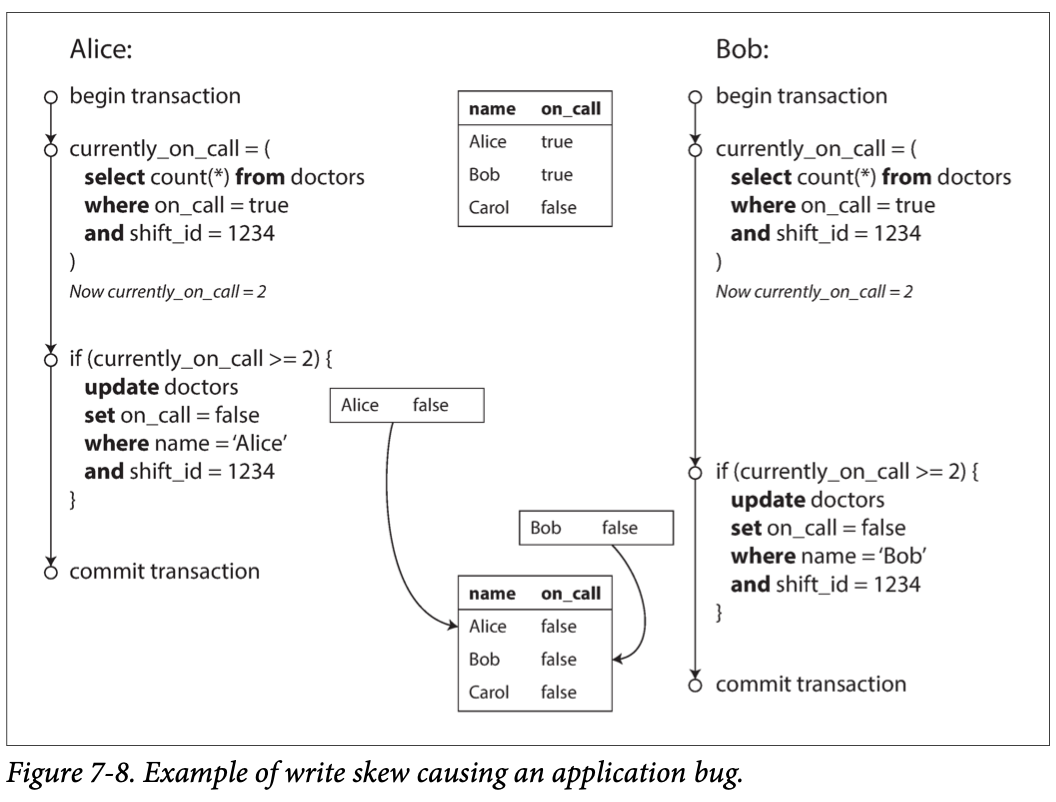
- 의사들의 호출 대기를 관리하는 애플리케이션이 있다.
- Alice와 Bob이 호출 대기를 하고 있을 때 둘 다 호출 대기를 그만두려고 하는데 동시에 호출 대기 상태를 끄게 되는 케이스에 쓰기 스큐가 발생할 수 있다.
- 각 트랜잭션의 첫 번째 쿼리에서 현재 호출 대기 중인 의사의 수를 확인한다.
- 데이터베이스에서 스냅숏 격리를 사용하고 있다면 둘 다
2를 반환하게 되므로 각각의on_call상태를false로 변경되고 트랜잭션은 커밋된다. - 이로 인해 호출 대기하는 의사가 한 명도 없게된다. 최소 한 명의 의사가 호출 대기해야 하는 요구사항을 위반했다.
- 이 케이스의 경우
SELECT절에FOR UPDATE를 붙여 로우를 명시적으로 잠그면 해결할 수 있다.
# 쓰기 스큐 패턴
- 쓰기 스큐가 발생하는 케이스들은 비슷한 패턴을 따른다.
SELECT질의가 어떤 조건에 부합하는 로우를 검색하여 요구사항을 만족하는지 확인한다.- 첫 번째 질의의 결과에 따라 애플리케이션 코드는 어떻게 진행할 지 결정된다.
- 계속 진행하는 것으로 결졍되었다면 데이터베이스에 쓰고 트랜잭션이 커밋된다. 이 쓰기의 효과로 2단계에 결정한 전제 조건이 변경된다.
- 호출 대기 예시에서는 3단계에서 변경되는 로우가 1단계에서 반환되는 로우 중 하나였다. 그래서 1단계에 잠금(SELECT FOR UPDATE)을 걸어 쓰기 스큐를 회피할 수 있다.
- 하지만 1단계 질의가 아무 로우도 반환하지 않아 잠금으로 해결할 수 없는 예시들이 존재한다.
- 이 패턴은 어떤 트랜잭션에서 실행한 쓰기가 다른 트랜잭션의 검색 질의 결과를 바꾸게 되는데 이런 효과를
팬텀(phantom)이라고 한다.- 스냅숏 격리는 읽기 전용 질의에서는 팬텀을 회피하지만 읽기 쓰기 트랜잭션에서는 팬텀이 쓰기 스큐를 유발할 수 있다.
# 잠금으로 해결할 수 없는 쓰기 스큐 예시
- 회의실 예약 시스템
- 회의실 예약 시스템은 중복된 예약을 방지해야 한다.
- 중복된 예약 방지를 위해선 예약 전 해당 시간대에 잡힌 예약이 있는지 확인해야 한다.
- 잡힌 예약이 없다는 아무 로우도 반환되지 않으므로 해당 로우를 잠글 수 없다.
- 잠금이 불가능한 경우 인위적으로 데이터베이스에 잠금 객체를 추가하여 팬텀을 잠금 충돌의 문제로 변환시키는
충돌 구체화전략이 있다.- 이 방법은 구체화하는 방법을 찾기 어렵고 오류가 발생하기 쉬우므로 최후의 수단으로 고려해야 한다.
- 대부분의 경우 직렬성 격리 수준으로 해결하는 것이 선호된다.
# 직렬성(Serializability)
직렬성 격리는 여러 트랜잭션이 병렬로 실행되더라도 결과는 한 번에 하나씩 직렬로 실행될 때와 같도록 보장한다.
직렬성을 제공하는 데이터베이스는 대부분 세 가지 기법 중 하나를 사용한다.
- 트랜잭션 직렬 실행
- 2단계 잠금
- 직렬성 스냅숏 격리(Serializable Snapshot Isolation)
# 1. 트랜잭션 직렬 실행
- 동시성 문제를 회피하기 위한 가장 간단한 방법은 실제로 동시성을 완전히 제거하는 것이다. 한 번에 트랜잭션이 하나씩만 실행되도록
단일 스레드에서 실행하면 된다. - 트랜잭션 직렬 실행은 몇 가지 제약 사항 안에서 직렬성 격리를 획득하는 실용적인 방법이다.
- 모든 트랜잭션은 작고 빨라야 한다. 느린 트랜잭션 하나가 모든 트랜잭션 처리를 지연시킬 수 있다.
- 활성화된 데이터셋을 메모리에 적재할 수 있어야 한다. 단일 스레드 트랜잭션에서 디스크에 접근하면 시스템은 매우 느려진다.
- 쓰기 처리량이 단일 CPU 코어에서 처리할 수 있을 정도여야 한다. 파티셔닝이 가능하지만 어느정도의 제한이 있다.
- 하드웨어 성능이 올라가 인메모리 데이터베이스 구현이 가능해졌고 OLTP 트랜잭션의 특성 상 쓰기 읽기 트랜잭션 시간이 짧고 로우 개수가 적기 때문에 단일 스레드 기반의 데이터베이스가 실현 가능해졌다.(참고 (opens new window))
- 단일 스레드 시스템은 오버헤드를 피할 수 있으므로 동시성을 지원하는 시스템보다 성능이 나을 떄도 있다. 하지만 처리량이 CPU 코어 하나의 처리량으로 제한되는 단점이 존재한다.
- 단일 스레드를 활용하기 위해서는 트랜잭션이 전통적인 현태와는 다르게 구조화 되어야 한다.
- 단일 스레드 시스템에서 기존 RDB의 상호작용식 트랜잭션을 사용하면 처리량이 매우 좋지 않을 것이다.
- 트랜잭션 코드 전체를
스토어드 프로시저(stored procedure)형태로 데이터베이스에 제출하는 방식을 사용한다.- 스토어드 프로시저를 사용하면 I/O 대기가 필요 없어 지므로 단일 스레드에서 좋은 처리량을 얻을 수 있다.
- 하지만 프로시저 코드를 관리하기 어렵고 애플리케이션에서 디버깅이 어려우며 프로시저를 잘못 작성하여 데이터베이스 성능에 영향을 줄 수 있다.
- 단일 스레드 시스템의 처리량을 높이기 위해 파티셔닝 기법을 활용하면 된다.(참고 (opens new window))
- 파티셔닝을 하는 경우 여러 파티션에 접근해야 하는 트랜잭션을 어떻게 처리할 지 고민이 필요하다.
- 여러 파티션에 걸친 트랜잭션은 잠금이 필요하므로 오버헤드가 있어 상당히 느릴 수 있다.
- 트랜잭션을 한 파티션에서 처리할 수 있도록 설계하는게 좋을 것이다.
# 2. 2단계 잠금(2PL)
- 데이터베이스에서 직렬성 구현을 위해 가장 많이 쓰인 알고리즘이 2단계 잠금(2-phase locking)이다.
- 2단계 잠금(2PL)과 2단계 커밋2PC(2PC)는 비슷하지만 완전히 다르다.(2PC 참고 (opens new window))
- 2PL은 쓰기 트랜잭션이 다른 쓰기 트랜잭션 뿐만아니라 읽기 트랜잭션도 진행하지 못하게 막는다.
- 트랜잭션 A가 객체 하나를 읽고 트랜잭션 B가 그 객체를 쓰려고한다면 A가 커밋되거나 어보트될 때 까지 기다려야 한다. (B가 A몰래 객체를 변경하지 못하도록 보장한다.)
- 트랜잭션 A가 객체에 썼고 트랜잭션 B가 그 객체를 읽기 원한다면 B는 진행하기 전에 A가 커밋되거나 어보트될 때 까지 기다려야 한다. (B가 과거 데이터를 읽지 않도록 보장한다.)
- 잠금 획득 오버헤드 뿐만 아니라 동시성이 줄어들기 때문에 다른 격리 수준에 비해 성능이 크게 나쁘다. 트랜잭션이 길수록 성능은 더 나빠진다.
# 2단계 잠금 구현
- MySQL(InnoDB)는 직렬성 격리 수준 구현을 위해 2PL을 사용한다.
- 데이터베이스의 각 객체에 잠금을 사용해 구현하고 잠금을
공유 모드(shared mode)와독점 모드(exclusive mode)로 구분한다.- 트랜잭션이 객체를 읽으려고 하면 먼저
공유 모드로 잠금을 획득해야 한다.- 여러 트랜잭션이
공유 모드잠금을 획득하는건 가능하나 이미 그 객체에독점 모드잠금을 획득한 트랜잭션이 있으면 해당 트랜잭션 완료까지 기다려야 한다.
- 여러 트랜잭션이
- 트랜잭션이 객체에 쓰기를 원한다면 먼저
독점 모드로 잠금을 획득해야 한다.공유 혹은 독점 모드잠금이 이미 있으면 다른 어떤 트랜잭션도 잠금을 획득할 수 없고 기다려야 한다.
- 트랜잭션이 객체를 읽다가 쓰려고 하면
공유 모드를독점 모드잠금으로 업그레이드 해야 한다.독점 모드잠금을 획득하는 과정과 동일하게 이루어진다.
- 트랜잭션이 잠금을 획득한 후에는 트랜잭션이 종료될 때 까지 잠금을 갖고 있어야 한다.
- 트랜잭션이 객체를 읽으려고 하면 먼저
- 2PL은 잠금이 많이 사용되므로 데드락이 발생할 가능성이 높아 데이터베이스는 데드락 감지를 통해 트랜잭션 중 하나를 어보트 시킬 수 있다.
# 서술 잠금(Predicate lock)과 색인 범위 잠금(Index-range lock)
- 회의실 예약 시스템 예시처럼 잠글 수 있는 객체가 없는 경우의 쓰기 스큐를 방지하기 위해선
서술 잠금이 필요하다. 서술 잠금은 특정 객체에 속하지 않고 어떤 검색 조건에 부합하는 모든 객체를 잠글 수 있다.- 트랜잭션 A가
SELECT질의의 어떤 조건에 부합하는 객체를 읽을 때공유 모드 서술 잠금을 획득해야 한다. 다른 트랜잭션이독점 잠금을 가지고 있다면 기다려야 한다. - 트랜잭션 A가 어떤 객체들을 쓰려고 할 때 해당 객체들에
서술 잠금에 부합하는게 있는지 확인해야 한다.서술 잠금을 다른 트랜잭션이 잡고 있다면 기다려야 한다.
- 트랜잭션 A가
- 2단계 잠금이 서술 잠금 까지 포함하면 모든 형태의 쓰기 스큐를 막을 수 있고 격리 수준이 직렬성 격리가 된다.
- 하지만 서술 잠금은 성능이 좋지 않아 대부분 2PL을 지원하는 데이터베이스는 서술 잠금을 간략하게 근사한
색인 범위 잠금을 구현한다.- 색인 범위 잠금은 더 많은 객체가 부합되도록 서술 조건을 간략화하여 잠금을 수행한다.
- 오후 1~2시에 1번 방을 예약하는 것에 대한 서술 잠금은 모든 시간 범위에 1번방을 예약하는 것에 대한 잠금으로 근사할 수 있다.
- 이때 방 번호에 대한 색인이 필요하다. 시간에 대해 색인이 있다면 시간으로 근사할 수 있을 것이다.
색인 범위 잠금은서술 잠금보다 정밀하지 않지만 오버헤드가 훨씬 더 낮기 때문에 좋은 타협안이 된다.
# 3. 직렬성 스냅숏 격리(Serializable Snapshot Isolation)
- 직렬성 격리 수준의 가장 큰 단점은 성능이다. 이 문제를 해결하기 위해 직렬성 스냅숏 격리가 유망하다.
- 2단계 잠금은
비관적동시성 제어 기법이지만 직렬성 스냅숏 격리는낙관적동시성 제어 기법이다. - 트랜잭션이 커밋되기를 원할 때 데이터베이스는 격리가 위반됐는지 확인하여 직렬성 격리 수준을 제공할 수 있다.
- 직렬성 스냅숏 격리는 경쟁이 심하면 어보트시켜야 할 트랜잭션이 늘어나므로 성능이 떨어진다. 하지만 경쟁이 심하지 않다면 비관적 방식보다 성능이 더 뛰어나다.
- 직렬성 스냅숏 격리는 스냅숏 격리를 기반으로 하기 때문에 모든 읽기는 데이터베이스의 일관된 스냅숏을 본다.
- 스냅숏 격리 위에 쓰기 작업 사이의 직렬성 충돌을 감지하여 어보트시킬 트랜잭션을 결정하는 알고리즘이 추가된다.
- 직렬성 충돌을 방지하기 위해 고려해야 하는 케이스는 두 가지가 있다.
# 1) 오래된 MVCC 읽기 감지
- 스냅숏 격리는 트랜잭션이 시작될 때 MVCC의 일관된 스냅숏을 기반으로 데이터를 읽기 때문에 다른 트랜잭션에서 커밋되지 않은 쓰기는 무시된다.
- 트랜잭션이 객체를 조회할 때 오래된 MVCC 객체를 읽었는지 감지한다. 감지된게 있다면 트랜잭션을 커밋할 때 데이터베이스는 해당 트랜잭션을 어보트시켜야 한다.
- 읽는 즉시 어보트하지 않고 커밋 시점에 하는 이유는 읽기 전용 트랜잭션이라면 쓰기 스큐의 위험이 없기 때문이다.
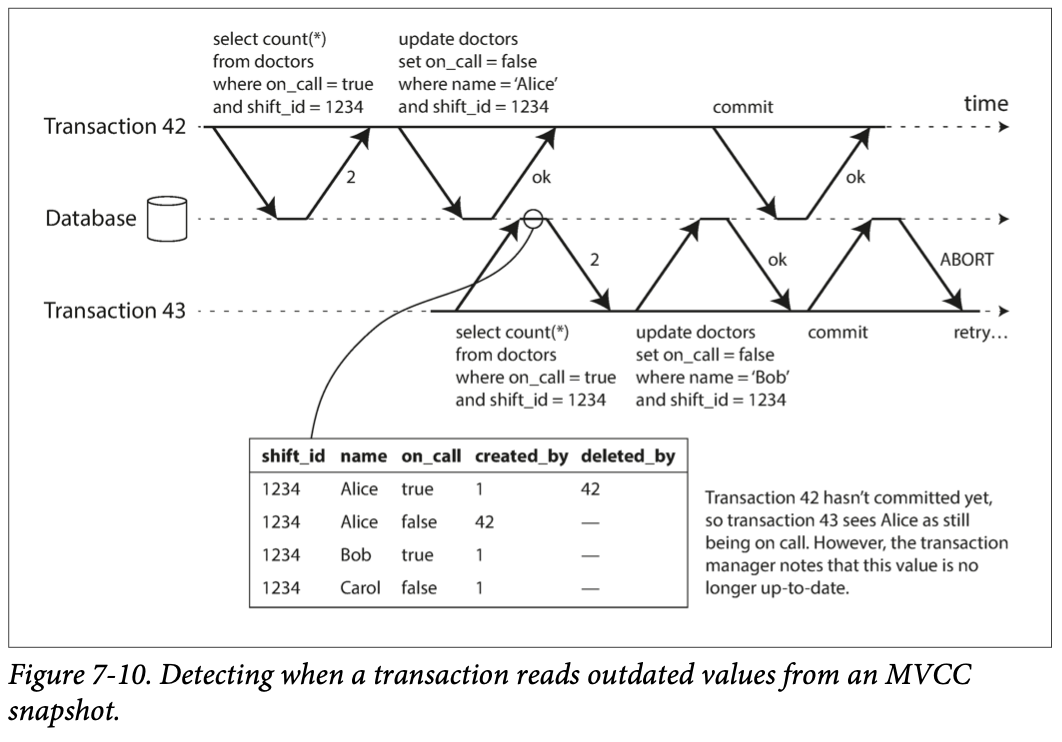
- 트랜잭션 43이
SELECT쿼리를 호출할 때 트랜잭션 42에 쓰기가 수행되었으므로 오래된 MVCC 객체를 읽을 것으로 본다. - 트랜잭션 43이 커밋하려고 할 때 트랜잭션 42는 커밋된 상태이므로 오래된 MVCC 객체를 읽은게 확실해졌으므로 트랜잭션을 어보트 시킨다.
# 2) 과거에 읽기에 영향을 미치는 쓰기 감지
- 트랜잭션이 객체를 읽은 후에 다른 트랜잭션에서 해당 객체를 썼는지를 감지한다. 감지된게 있다면 트랜잭션을 커밋할 때 데이터베이스는 해당 트랜잭션을 어보트시켜야 한다.
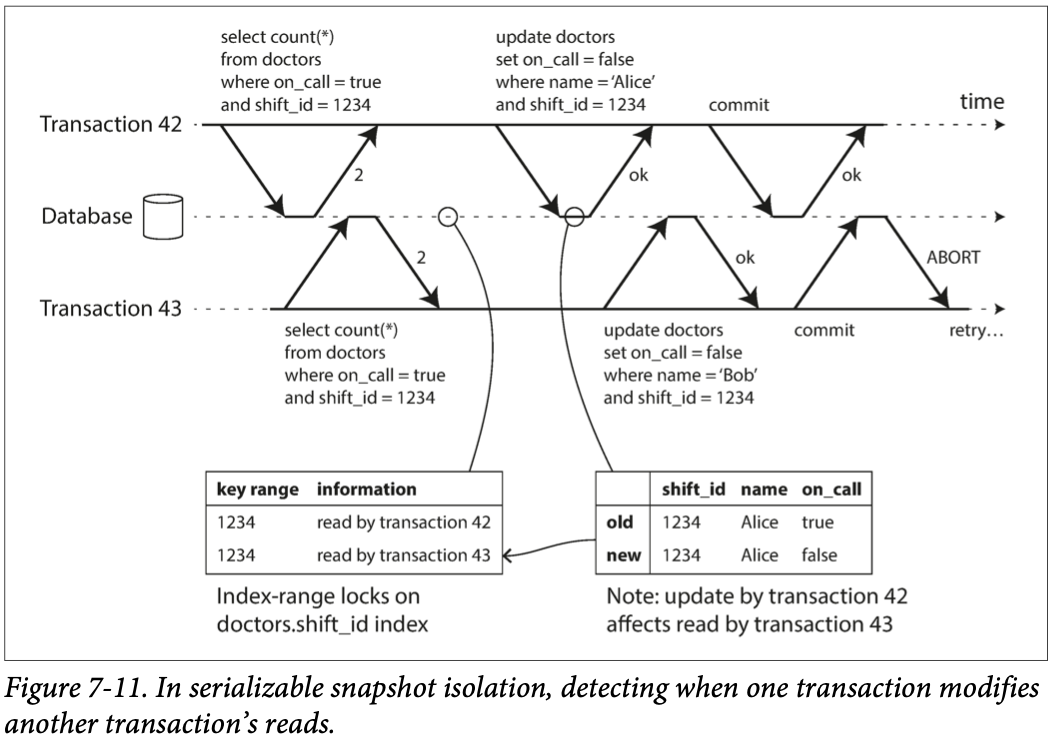
- 트랜잭션 42, 43에서
SELECT쿼리를 호출할 때 색인 범위 잠금 기법을 통해 트랜잭션 42, 43이 객체를 읽었다는 사실을 기록한다.- 해당 색인 잠금은 2단계 잠금과 다르게 트랜잭션을 차단하지 않는다.
- 트랜잭션 42가 객체를 쓸 때 해당 객체를 최근에 읽은 트랜잭션이 있는지를 색인 범위 잠금에서 확인한다. 그리고 각 트랜잭션에게 해당 데이터가 더 이상 최신이 아니라고 알려준다.
- 트랜잭션 42가 먼저 커밋을 시도해 성공하였으므로 트랜잭션 43이 커밋을 하려고하면 해당 트랜잭션을 어보트 시킨다.
# 직렬성 스냅숏 격리의 성능
- 2단계 잠금과 비교하여 트랜잭션이 다른 트랜잭션을 기다리느라 차단되지 않기 때문에 읽기 작업이 많은 경우 성능이 더 뛰어나다.
- 트랜잭션의 읽기 쓰기를 추적하는 세밀함에 따라 기록 오버헤드가 달라진다. 덜 상세하게 추적하면 오버헤드가 작아 속도는 빠르겠지만 많은 트랜잭션이 어보트될 수 있다.
- 어보트 비율은 성능에 큰 영향을 미친다. 오랫동안 데이터를 읽고 쓰는 트랜잭션은 충돌 가능성이 높아 어보트되기 쉬우므로 읽기-쓰기 트랜잭션이 짧을 수록 유리하다.(읽기 전용 트랜잭션은 문제 없다.)
# 정리
트랜잭션이 없으면 다양한 오류 시나리오에서 다양한 방법으로 일관성이 깨질 수 있다. 비정규화된 데이터는 원천 데이터와 동기화가 깨지기 쉬우나 트랜잭션이 있다면 원자적으로 동작하여 동기화를 이룰 수 있다.
# ACID
- 원자성(Atomicity)
- 한 트랜잭션에서 발생한 쓰기들은 모두
완료(커밋)되거나 결함 발생 시 모두중단(어보트)되거나 둘 중 하나여야 한다.
- 한 트랜잭션에서 발생한 쓰기들은 모두
- 일관성(Consistency)
- 트랜잭션이 완료될 때 데이터에 관한
불변식이 반드시 만족되어야 한다.
- 트랜잭션이 완료될 때 데이터에 관한
- 격리성(Isolation)
- 동시에 실행되는 트랜잭션은 서로 격리되어야 한다. 트랜잭션은 다른 트랜잭션을 방해할 수 없다.
- 지속성(Durability)
- 트랜잭션이 성공적으로 커밋됐다면 트랜잭션에서 기록한 모든 데이터는 손실되지 않고 지속되어야 한다.
# 격리 수준
- 커밋 후 읽기(read commited)
- 스냅숏 격리(snapshot isolation)=반복 읽기(repeatable read)
- 직렬성 격리(serializable)
# 경쟁 조건(Race Condition)
- 더티 읽기
- 다른 트랜잭션에서 썼으나 커밋되지 않은 데이터를 읽는다. 커밋 후 읽기와 그 보다 높은 격리 수준은 더티 읽기를 방지한다.
- 더티 쓰기
- 다른 트랜잭션이 썼지만 아직 커밋되지 않은 데이터를 덮어쓴다. 거의 모든 트랜잭션 구현은 더티 쓰기를 방지한다. 로우 수준 잠금이 가장 흔한 구현 방식이다.
- 읽기 스큐(비반복 읽기)
- 한 트랜잭션에서 같은 데이터를 여러번 조회할 때 다른 트랜잭션의 쓰기로 인해 결과가 달라진다. 보통 스냅숏 격리를 통해 방지한다. 스냅숏 격리는 주로 다중 버전 동시성 제어(MVCC)를 써서 구현한다.
- 갱신 손실
- 두 트랜잭션이 동시에 읽기-수정-쓰기(read-modify-write)를 수행할 때 한 트랜잭션이 다른 트랜잭션의 변경을 포함하지 않은채로 덮어써서 데이터가 손실된다.
- 이를 자동으로 감지하고 막아주는 데이터베이스가 있지만 그렇지 않다면 명시적인 잠금이나 방지 가능한 연산을 활용해야 한다.
- 쓰기 스큐
- 동시에 실행되는 두 트랜잭션이 같은 객체들을 읽어서 그중 일부를 갱신하는데 각각 다른 객체들을 갱신하여 애플리케이션의 요구사항을 위반한다.
- 직렬성 격리만이 이런 현상을 막을 수 있다.
- 팬텀 읽기
- 트랜잭션이 어떤 검색 조건에 부합하는 객체를 읽는다. 다른 트랜잭션이 그 검색 결과에 영향을 주는 쓰기를 실행하여 결과가 달라진다.
- 스냅숏 격리는 간단한 팬텀 읽기는 막아주지만 쓰기 스큐 맥락에서 발생하는 팬텀은 색인 범위 잠금과 같은 특별한 처리가 필요하다.
# 직렬성 격리 구현
- 트랜잭션 직렬 실행
- 단일 스레드에서 트랜잭션을 순서대로 실행한다.
- 트랜잭션 실행 시간이 아주 짧고 처리량이 단일 CPU 코어에서 처리할 수 있을 정도면 효과적인 선택이다.
- 2단계 잠금
- 2단계 잠금 기법으로 다른 트랜잭션 진행을 막는다. 주로 사용되던 방식이지만 성능 특성 때문에 선호되지 않는다.
- 직렬성 스냅숏 격리
- 낙관적 방법을 사용하여 트랜잭션을 차단하지 않고 트랜잭션 커밋 시 충돌을 확인하여 충돌 시 트랜잭션을 어보트 시킨다.