데이터 중심 애플리케이션 설계 Ch 6. 파티셔닝
# 파티셔닝과 복제
데이터셋이 매우 크거나 질의 처리량이 매우 높다면 복제만으로 부족하고 데이터를 파티션으로 쪼갤 필요가 있다. 이 작업을 샤딩이라고 한다.
여기서 말하는 파티션은 몽고DB, ES의 샤드(shard)에 해당한다. HBase에서는 리전(region), 빅테이블에서는 태블릿(tablet), 카산드라와 리악에서는 브이노드(vnode)이다.
각 파티션은 그 자체로 작은 데이터베이스가 되며 각 노드에서 자신의 파티션에 해당하는 질의를 독립적으로 실행할 수 있으므로 노드를 추가함으로써 질의 처리량을 늘릴 수 있다.
데이터 파티셔닝의 주된 이유는 확장성이다.
보통 복제와 파티셔닝을 함께 적용해 각 파티션의 복사본을 여러 노드에 저장한다.(한 노드에 여러 파티션을 저장하기도 한다.)
# 키-값 데이터 파티셔닝
파티셔닝의 목적은 데이터와 질의 부하를 노드 사이에 고르게 분산시키는 것이다.
- 파티셔닝이 고르게 이루어지지 않아 한 파티션이 많은 데이터를 가지거나 많은 질의를 받는다면
쏠렸다(skewed)고 말하며 불균형하게 부하가 높은 파티션을핫스팟이라고 한다. - 어떤 레코드를 어느 노드에 저장할지 어떻게 결정해야 할까?
# 1. 키 범위 기준 파티셔닝
- 백과사전처럼 각 파티션에 연속된 범위의 키를 할당하는 방식이다.
- 각 범위들의 경계를 알면 어떤 키가 어느 파티션에 속하는지 쉽게 찾을 수 있다.
- 그러나 키 범위 기준 파티셔닝은 특정한 접근 패턴이 핫스팟을 유발하는 단점이 있다.
- 특정 키 범위에만 부하가 몰려 특정 파티션에만 과부화가 걸릴 수 있다.
- HBase, 리싱크DB, 2.4버전 이전의 몽고DB에서 사용된다.
# 2. 키의 해시값 기준 파티셔닝
쏠림과핫스팟의 위험 때문에 많은 분산 데이터스토어는 키의 파티션을 정하는 데해시 함수를 사용한다.- 좋은 해시 함수는 쏠린 데이터를 균일하게 분산시킨다.
- 파티셔닝용 해시 함수는 암호학적으로 강력할 필요는 없다. 카산드라는 MD5를 사용한다.
- 키 범위 파티셔닝에 비해 키의 해시 값 기준 파티셔닝은 범위 질의를 효율적으로 실행할 수 없다.
- 카산드라의 경우 두 전략을 모두 활용한다.
primary key를 통해 파티션을 결정하고clustering key를 통해 SS테이블에서 데이터가 정렬되도록 하여primary key를 지정한다면 범위 질의를 효율적으로 실행할 수 있다.
# 쏠린 작업부하와 핫스팟 완화
- 해시값 기준 파티셔닝은 핫스팟을 줄여주지만 동일한 키를 읽고 쓰는 극단적 상황에서는 핫스팟이 발생할 수 있다.
- 현대 데이터 시스템은 대부분 크게 쏠린 작업부하를 자동으로 보정하지 못하므로 애플리케이션에서 쏠림을 완하해야 한다.
- 키의 끝에 임의로 숫자를 붙일 수 있다.
# 파티셔닝과 보조 색인(secondary index)
보조 색인은 보통 레코드를 유일하게 식별하는 용도가 아닌 특정한 값이 발생한 항목을 검색하는 수단이다.
보조 색인은 RDB에서 핵심 요소이며 솔라나 엘라스틱서치와 같은 검색 서버에서 존재의 이유다.
- 많은 키-값 저장소에서는 구현 복잡도로 인해 지원하지 않는다.
보조 색인은 파티션에 깔끔하게 대응되지 않는 문제점이 있고, 보조 색인이 있는 데이터베이스를 파티셔닝하는데 널리 쓰이는 두 가지 방법이 있다.
# 1. 문서 기준 보조 색인 파티셔닝
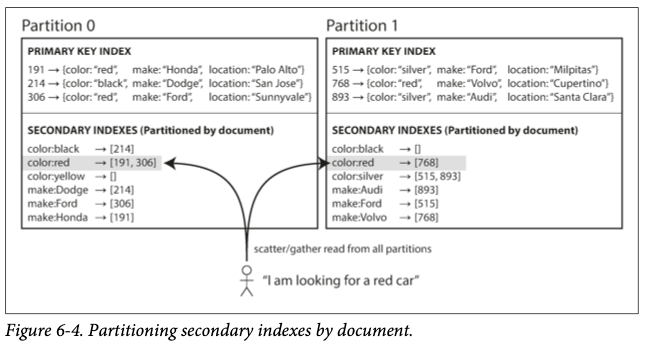
- 각 항목에는 고유한 document ID가 있고 데이터베이스를 document ID 기준으로 파티셔닝한다.
- 이 방식은 파티션별 자신의 보조 색인을 유지하는 방식으로 각 파티션이 완전히 독립적으로 동작한다.
- 이러한 특징으로 인해 문서 파티셔닝 색인은
지역 색인(local index)라고도 한다.
- 이러한 특징으로 인해 문서 파티셔닝 색인은
- 문서 파티셔닝 색인은 보조 색인으로 검색하기 위해 모든 파티션에 질의를 보내서 얻을 결과를 모두 모아야 한다.
- 이런 방식을
스캐터/개터(scatter/gather)라고 한다. - 보조 색인으로 검색 시 큰 비용이 들 수 있지만 보조 색인을 문서 기준으로 파티셔닝하는 경우가 많다.
- 몽고DB, 리악, 카산드라, ES 등은 모두 문서 기준으로 파티셔닝된 보조 색인을 사용한다.
- 이런 방식을
# 2. 용어 기준 보조 색인 파티셔닝
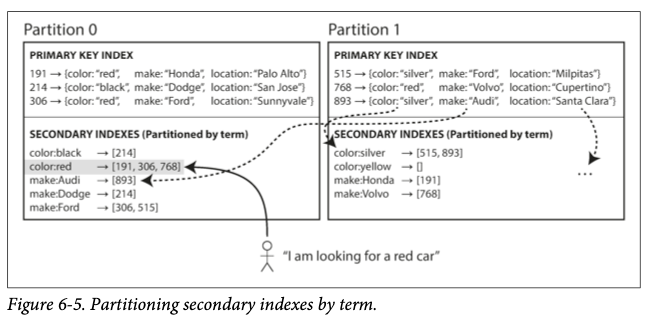
- 각 파티션이 자신만의 보조 색인(지역 색인)을 갖는 대신 모든 파티션을 담당하는
전역 색인을 가진다.- 전역 색인 또한 파티셔닝이 필요하지만 기본키 색인과는 다른식으로 할 수 있다.
- 찾고자 하는 용어에 따라 색인의 파티션이 결정되므로
용어 기준 보조 색인 파티셔닝이라고 하며color:red가 예이다.- 문서 기준 보조 색인 파티셔닝에서는
color:red색인이 각 파티션별 따로 존재했지만 여기선 파티션 0에만 존재한다.
- 문서 기준 보조 색인 파티셔닝에서는
- 색인이 한 파티션에 존재해 문서 기준 보조 색인 파티셔닝보다 읽기가 효율적이지만 쓰기가 느리고 복잡하다는 단점이 있다.
- 단일 문서를 쓸 때 색인으로 인해 여러 파티션에 영향을 줄 수 있다.
- 이상적인 색인이라면 항상 최신 상태에 있어야 하지만 용어 파티셔닝 색인을 사용하면 분산 트랜잭션이 필요해지고 이는 모든 데이터베이스에서 지원되지 않고 현실적으로 비동기로 수행된다.
- 대표적인 사용처는 리악, 오라클 데이터 웨어하우스가 있다.
# 파티셔닝과 재균형화(리밸런싱)
시간이 지나면 데이터베이스에 변화가 생기고 새로운 노드 추가가 필요해진다.
- 높은 부하를 처리하기 위해
- 데이터셋 크기가 증가
- 장애로 인한 노드 변경
클러스터에서 한 노드가 담당하던 부하를 다른 노드로 옮기는 과정을 재균형화(리밸런싱)라고 한다.
리밸런싱이 일어날 때 보통 기대하는 최소 요구사항은 다음과 같다.
- 리밸런싱 후 부하가 균등하게 분배되어야 한다.
- 리밸런싱 도중에도 읽기 쓰기 요청이 가능해야 한다.
- 노드들 사이에 데이터가 필요 이상으로 옮겨져서는 안된다.
리밸런싱 전략을 살펴보자.
# 1. 해시값에 mod N 연산 수행(쓰면 안됨)
- mod N 방식은 N(노드 개수)이 바뀌면 대부분의 키가 노드 사이에 옮겨져야 해 리밸런싱 비용이 지나치게 커진다.
(123456 mod 10 = 6),(123456 mod 11 = 3),(123456 mod 12 = 0)- N이 증가할 때 마다 대상 노드가 계속 바뀌기 때문에 비효율적이다.
# 2. 파티션 개수 고정
- 파티션을 노드 대수보다 많이 만들고 각 노드에 여러 파티션을 할당하여 데이터를 최소한으로 이동시킬 수 있다.
- 클러스터에 노드가 추가되면 새 노드는 기존 노드에서 파티션을 몇개 뺏어와 파티션을 균일하게 맞춘다.
- 파티션은 노드 사이에서 통째로 이동하기만 한다. 파티션 개수는 바뀌지 않고 파티션에 할당된 키도 변경되지 않는다.
- 오직 노드에 어떤 파티션이 할당되는가만 변경된다.
- 이 방식을 사용할 땐 보통 처음 데이터베이스가 구축될 때 파티션 개수를 고정하고 그 이후에 변경하지 않는다.
- 파티션 개수를 고정하면 운영이 단순해지므로 분할을 지원하지 않는 경우도 많다.
- 파티션이 너무 크면 리밸런싱 및 복구의 비용이크고, 너무 작으면 오버헤드가 커진다.
- 파티션 크기가
딱 적당할 때성능이 가장 좋지만 데이터셋 크기는 변하고 파티션 개수는 고정되어 있어 크기를 정하기 어려울 수 있다.
# 3. 동적 파티셔닝
- 키 범위 파티셔닝을 사용하는 경우 파티션 경계를 잘못 지정하면 파티션 쏠림이 발생할 수 있어 파티션 경계와 개수가 고정되어 있는 방식은 매우 불편하다.
- 이런 경우 파티션 크기가 설정된 값을 넘어설 때 파티션을 두 개로 쪼개어 동적 파티셔닝을 할 수 있다.
- 임계값 아래로 떨어지면 다시 합친다.
- 키 범위 파티셔닝을 사용하는 HBase나 리싱크DB등이 동적 파티셔닝을 사용한다.
- 동적 파티셔닝은 파티션 개수가 전체 데이터 용량에 맞춰 조정되는 이점이 있다.
- 단, 데이터베이스 시작 시점에 파티션 경계를 나눌 사전 정보가 없어 파티션이 하나가 된다.
- 이를 해결하기 위해 빈 데이터베이스에 초기 파티션 집합을 설정할 수 있도록 지원한다.
- 동적 파티셔닝은 키 범위 파티셔닝뿐만 아니라 해시 파티셔닝에서도 똑같이 활용될 수 있다.
# 4. 노드 비례 파티셔닝
- 이 방식은
노드 당 할당되는 파티션 개수를 고정하여 노드의 증감유무에 따라 파티션의 크기가 달라지도록 한다.- 카산드라에서 사용하는 방식으로 노드가 유지될 때는 개별 파티션의 크기가 데이터셋 크기에 따라 증가하지만 노드 대수를 늘리면 다시 작아진다.
- 이전의 두 방식은 노드에 독립적으로 데이터셋 크기에 따라 파티션의 크기와 파티션의 수가 증가하지만 이 방식은 노드 수에 따라 파티션의 크기가 변화한다.
- 새 노드가 추가되면 고정된 개수의 파티션을 무작위로 선택해 분할하고 분할된 각 파티션의 절반은 그대로 두고 다른 절반은 새 노드에 할당한다.
# 운영: 자동 리밸런싱과 수동 리밸런싱
- 완전 자동 방식은 유지보수가 덜하겠지만 예측이 어렵다.
- 트래픽 증가로 인해 일시적인 장애로 응답이 느려졌는데 노드가 죽었다고 판단해 리밸런싱이 발생하여 더 많은 부하를 줘 상황을 더 악화시킬 수 있다.
- 이런 이유로 리밸런싱 과정에 사람이 개입하는게 좋을 수 있다. 완전 자동보단 느리겠지만 운영상 예상치 못한 일을 방지하는데 도움이 될 수 있다.
# 요청 라우팅
클라이언트에서 요청을 보내려고할 때 어느 노드에 접속해야하는지 어떻게 알 수 있을까?
파티션은 리밸런싱되어 노드에 할당되는 파티션이 바뀌는데 어떻게 알 수 있을까?
이를 위해 크게 3 가지 접근법이 있다.
- 클라이언트가 아무 노드에나 접속하게 하고 해당 노드에서 대상 노드로 요청을 전달하고 응답을 받아 클라이언트에게 응답해준다.
- 클라이언트의 모든 요청을 라우팅 계층으로 보내고, 각 라우팅 계층에서 대상 노드를 찾아 라우팅한다.
- 클라이언트가 노드의 정보를 알고있도록 하여 클라이언트가 알아서 판단해서 대상 노드로 요청을 보내도록 한다.
위 방식 모드 핵심 문제는 라우팅 결정을 내리는 구성요소가 노드에 할당된 파티션의 변경을 어떻게 아는지이다.
- 많은 분산 데이터 시스템은 클러스터 메타데이터를 추적하기 위해 주키퍼와 같은 코디네이션 서비스를 사용한다.
- HBase, 카프카등이 주키퍼를 사용한다.
카산드라와 리악은가십 프로토콜(gossip protocol)을 사용하여 클러스터 상태 변화를 노드 사이에 퍼트린다.- 노드간 상태 변화를 주고받기 때문에 1번 방식을 사용해야 한다.
- 데이터베이스에 복잡성은 증가하지만 주키퍼와 같은 외부 코디네이션 서비스에 의존하지 않는다.
# 정리
파티셔닝의 목적은 데이터와 질의 부하를 여러 노드에 균일하게 분배하는 것이다.
# 두 가지 주요 파티셔닝 기법
# 1. 키 범위 파티셔닝
- 키가 정렬돼 있어 범위 질의가 효율적이지만 핫스팟이 생길 위험이 있다.
- 한 파티션이 너무 커지면 키 범위를 두 개로 쪼개는 동적 파티셔닝을 통해 리밸런싱 한다.
# 2. 해시 파티셔닝
- 해시 함수를 통해 키를 균일하게 분산시킬 수 있지만 범위 질의가 비효율적이다.
- 노드 수 보다 많은 고정된 개수의 파티션을 미리 정해놓고 파티션을 통째로 노드 사이에서 이동하는 리밸런싱 방식을 주로 사용한다.
# 두 가지 보조 색인 파티셔닝 기법
# 1. 문서 파티셔닝 색인(지역 색인)
- 보조 색인을 기본키와 값이 저장된 파티션에 함께 저장하기 때문에 쓰기 시 단일 파티션만 수정하면 되지만 읽기 시 모든 파티션을 조회해야 하므로 비효율적이다.
# 2. 용어 파티셔닝 색인(전역 색인)
- 보조 색인을 별도로 파티셔닝하여 단일 파티션에 저장하기 때문에 읽기 시 단일 파티션만 조회하면 되지만 쓰기 시 여러 파티션에 영향을 줄 수 있다.
← Ch 5. 복제 Ch 7. 트랜잭션 →