데이터 중심 애플리케이션 설계 Ch 9. 일관성과 합의
작성일: 2022-01-26T22:23:57.000Z
# 선형성(강력한 일관성, Strong Consistency)
최종적 일관성을 지닌 데이터베이스에서 두 개의 다른 복제본은 서로 다른 데이터를 가지고 있을 수 있다.
선형성 시스템에서는 클라이언트가 쓰기를 성공적으로 완료하자마자 그 데이터베이스를 읽는 모든 클라이언트는 새 값을 볼 수 있어야 한다.
- 클라이언트는 반드시 하나의 일관된 최신 상태만을 관찰할 수 있어야 한다.
즉, 선형성은 최신성 보장이라고 할 수 있다.
# 선형성 대 직렬성
- 직렬성은 모든 트랜잭션이 여러 객체를 읽고 쓸 수 있는 상황에서의 트랜잭션의 격리 속성이다.
- 선형성은 레지스터(개별 객체)에 실행되는 읽기와 쓰기에 대한 최신성 보장이다.
- 직렬성이 보장된다고 선형성이 반드시 보장되진 않는다.
# 잠금과 리더 선출
- 단일 리더 복제 시스템은 리더가 여러 개(스플릿 브레인)가 아니라 반드시 하나만 존재하도록 보장해야 한다.
- 리더를 선출하는 방법으로 잠금을 사용할 수 있고 이 잠금은
선형적이어야 한다.- 분산 잠금과 리더 선출을 위해 아파치 주키퍼나 etcd 같은 코디네이션 서비스가 종종 사용된다.
# 제약 조건과 유일성 보장
- 데이터베이스에서 흔하게 사용되는 유일성 제약 조건도 잠금과 비슷하게
선형성을 필요로 한다.
# 선형성 시스템 구축하기
# # 단일 리더 복제
- 단일 리더 복제는 팔로워를 동기식으로 복제한다면
선형적이 될 수 있다. - 비동기 복제를 사용하는 경우 장애 복구 시 쓰기가 손실될 가능성이 있으므로 지속성과 선형성 모두 위반한다.
# # 다중 리더 복제
- 다중 리더 복제는 일반적으로 선형적이지 않다. 보동 비동기로 복제를 진행하기 때문이다.
# # 리더 없는 복제
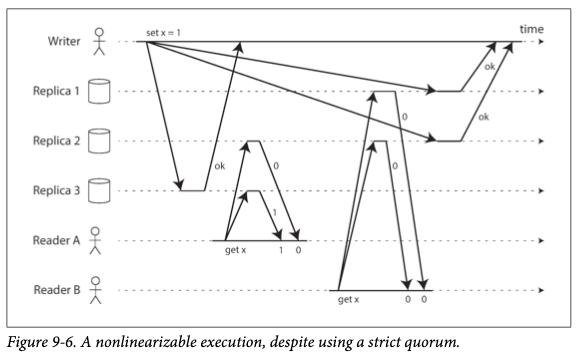
- 카산드라와 같은 다이나모 스타일 모델에서 정족수를 사용한 읽기 쓰기는 선형적인 것처럼 보이지만 에지 케이스(네트워크 지연)에 의해 경쟁 조건이 생길 가능성이 존재한다.
- 위 예시는 각 클라이언트가 정족수 읽기 및 쓰기를 수행하므로 선형성(Strong Consistnecy) 조건을 만족(w + r > n)하지만
선형적이지 않다.- 카산드라는 위 상황에서 읽기 복구를하기 때문에 A가 읽을 때 Replica 2가 복구되기 때문에 B는 최신 데이터를 받을 수 있다.
- 만약 Reader A가 Replica 1, Replical 2에 요청을 했다면 오래된 데이터를 받게되어 선형성을 만족하지 못할 것이다.
Read: ALL/ONE, Write: ONE/ALL인 경우 선형성을 만족할 수 있을 것이다.
- 하지만, 카산드라는 최종 쓰기 승리 충돌 해소 방법을 사용하기 때문에 같은 키에 동시에 여러 쓰기가 들어오면 선형성을 보장할 수 없게 된다.
- 카산드라는 위 상황에서 읽기 복구를하기 때문에 A가 읽을 때 Replica 2가 복구되기 때문에 B는 최신 데이터를 받을 수 있다.
- 다이나모 스타일을 사용하는 리더 없는 복제 시스템은
선형성을 보장할 수 없다고 보는 것이 안전하다.- 카산드라의 경우 Writer의 정족수 쓰기 요청은 두번째 노드에 쓰기가 수행될 때 까지 완료되지 않을 것이다.
- Writer 입장에서 쓰기 요청이 완료되지 않았다고 하더라도 노드들 간의 데이터의 일관성이 맞지 않아 다른 클라이언트는 오래된 데이터를 볼 수 없으므로 선형성을 보장할 수 없다고 보는 것이 맞다.
# 선형성의 비용
- 두 데이터센터의 데이터베이스 간에 복제를 진행하고 있을 때 두 데이터센터 사이에 네트워크가 끊기면 무슨일이 생길지 생각해보자.
- 여기서 각 데이터센터 내부 네트워크는 동작하여 클라이언트들은 데이터센터에 접근할 수 있으나 데이터센터끼리만 연결이 불가능하다고 가정한다.
- 이 경우 선형성과 가용성 사이에서 선택해야 한다.
- 선형성을 선택하면 두 데이터센터간에 복제가 불가능하기 때문에 어떤한 쓰기도 수행되어선 안된다.
- 가용성을 선택하면 두 데이터센터간에 복제가 불가능하여 데이터의 일관성이 깨질 수 있지만 쓰기 동작을 수행할 수 있게 된다.
- 가용성을 제공하는 다중 리더 데이터베이스 시스템이라면 이 상황에서도 각 데이터센터는 계속 정상 동작할 것이다.
- 반면, 단일 리더 복제를 사용하는 경우 데이터센터 간 네트워크가 끊겼기 때문에 모든 쓰기가 중단되고 팔로워로 부터 읽는 데이터의 선형성이 보장되지 않는다.
# CAP 정리
- 흔히 CAP 정리는 일관성(Consistency), 가용성(Availability), 분단 내성(Partition tolerance) 중 두 개를 고를 수 있다고 표현되지만 이는 오해의 소지가 있다.
- 네트워크 분단은 결함이므로 선택할 수 있는 것이 아니고 반드시 발생하기 때문에 분단 내성은 반드시 고려되어야 한다.
- 즉 CAP 정리는
네트워크 분단(P)이 생겼을 때일관성(C)과가용성(A)중 하나를 선택할 수 있다고 보는게 좋다. - 여기서 일관성은 선형성(Strong Consistency)로 보는 것이 옳다.
- 만약 애플리케이션에서 선형성이 요구된다면 네트워크 분단 시 가용성을 보장할 수 없게 된다. 반대로 애플리케이션에서 선형성을 요구하지 않는다면 네트워크 분단 시 선형적이지 않지만 가용한 상태를 제공할 수 있다.
- 선형성이 필요 없는 애플리케이션은 네트워크 문제에 더 강인하다.
# 선형성과 네트워크 지연
- 선형성을 보장하기 위해서는 읽기와 쓰기 요청의 응답 시간이 네트워크 지연에 크게 영향을 받을 수 밖에 없다.
- 네트워크는 신뢰성이 없기 때문에 지연 시간에 민간함 시스템에서는 선형성을 보장하기 어려울 수 밖에 없다.
- 선형성을 포기하면 네트워크 지연에 덜 영향을 받으므로 훨씬 더 빠를 수 있다. 트레이드 오프가 필요하다.
# 순서화 보장
# 순서화와 인과성
- 순서화는 인과성을 보존하는 데 도움을 준다. 인과성이 중요한 경우가 있다.
- 인과성이 지켜지지 않으면 대화의 관찰자가 질문보다 그 질문의 응답의 먼저 볼 수 있다.
- 인과성은 이벤트에 순서를 부과한다. 결과가 나타나기 전에 원인이 발생한다.
- 메시지를 받기 전에 메시지를 보낸다.
- 답변하기 전에 질문을 한다.
- 시스템이 인과성에 의해 부과된 순서를 지키면 그 시스템은
인과적으로 일관적(causally consistent)이라고 한다.- 스냅숏 격리는 인과적 일관성을 제공한다.
- 데이터베이스에서 읽어서 데이터의 어떤 조각을 봤다면 그보다 인과적으로 먼저 발생한 어떤 데이터도 볼 수 있어야 한다.
# 선형성 vs 인과성
- 선형성 시스템에서는 연산의 전체 순서를 정할 수 있다.
- 모든 연산이 최신성이 보장되므로 두 연산에 대해 어떤 연산이 먼저 실행되었는지 확신할 수 있다.
- 즉, 선형성 데이터스토어에는 동시적 연산이 없다.
- 인과성은 전체 순서가 아닌 부분 순서만을 정할 수 있다.
- 두 연산에 인과적인 관계(질문과 답변)가 있으면 이들의 순서를 정할 수 있지만 그렇지 않으면 순서를 정할 수 있다.
- 선형성은 전체 순서를 정할 수 있기 때문에 인과성을 내포한다.
- 하지만 선형성을 보장하기 위해서는 성능과 가용성에 해가 될 수 있다.
- 선형성은 인과성을 보존하는 유일한 방법이 아니므로 인과성을 위해서는 다른 방법을 고려해볼 수 있다.
# 인과적 일관성 아이디어
# 1) 일련번호 순서화
- 일련번호나 타임스탬프를 사용하여 이벤트의 순서를 정할 수 있다.
- 단일 리더 시스템에서는 하나의 리더의 기반으로 결정되므로 순서를 정할 수 있으나 단일 리더 시스템이 아니라면 이 방식은 인과적 일관성을 보장할 수 없다.
- 일련번호를 위해 쓰기 노드별로 특별한 규칙을 정해서 중복이 발생하지 않도록 할 수 있지만 인과성에 일관적이지 않다.
- 타임스탬프를 활용하더라도 해상도가 충분하지 않다면 인과성에 일관적이지 않다.
# 2) 램포트 타임스탬프
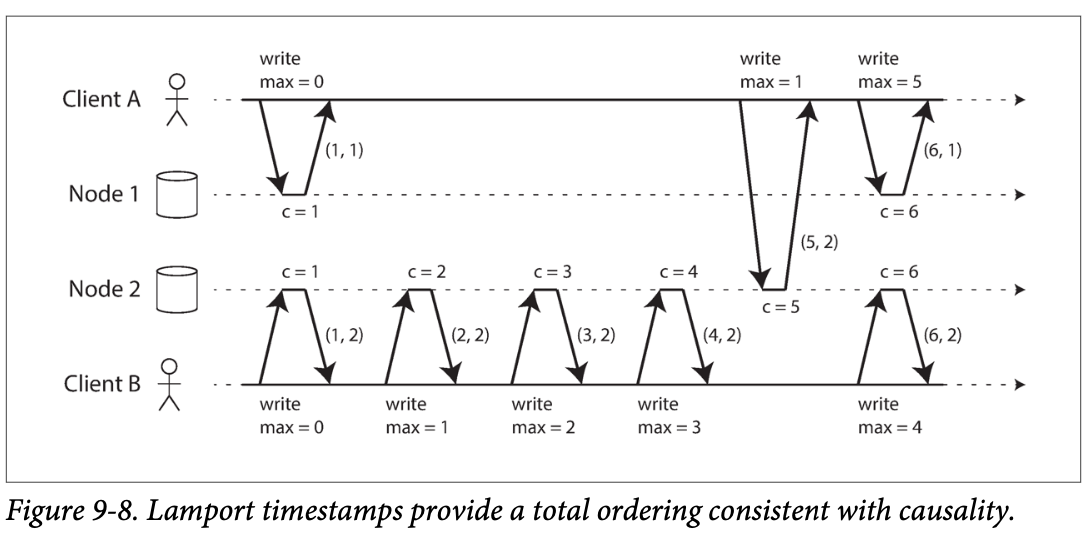
- 램포트 타임스탬프를 할용해서 분산 시스템에서 일관적인 일련번호를 생성할 수 있다.
- 램포트 타임스탬프는
(카운터, 노드 ID)쌍을 가져 각 노드의 카운터 값이 같더라도노드 ID기반으로 식별이 가능하도록 한다.- 각 노드 별로 처리한 연산 개수를 카운터로 유지한다.
- 램포트 타임스탬프는 일 기준 시계와 관련이 없지만 전체 순서화를 제공한다.
- 카운터가 큰 것이 타임 스탬프가 크다.
- 카운터 값이 같으면 노드 ID가 큰 것이 타임 스탬프가 크다.
- 이 방식을 지원하기 위해서는 모든 노드와 클라이언트가 카운터 최댓값을 추적하고 모든 요청에 그 최대값을 포함시켜야 한다.
- 해당 최대값을 기반으로 각 노드는 자신의 카운터를 그 최대값으로 동기화하여 언제나 모든 노드가 최대값을 알 수 있도록 한다.
- 타임스탬프 순서화는 모든 연산이 처리되고 그 연산을 모은 후에 순서가 드러나기 때문에 유일성 제약 조건과 같은 구현에서 사용할 수 없다.
# 3) 전체 순서 브로드캐스트
- 전체 순서 브로드캐스트를 통해 유일성 제약 조건을 구현할 수 있다.
- 전체 순서 브로드캐스트는 노드 사이에 메시지를 교환하는 프로토콜로 기술된다.
- 전체 순서 브로드캐스트 알고리즘은 노드나 네트워크에 결함이 있더라도 신뢰성(정확히 한번)과 순서화 속성이 항상 만족되도록 보장해야 한다.
- 결함 당시엔 메시지 전달이 불가하더라도 재시도를 통해 복구 시 순서에 맞게 전달이 가능하도록 해야 한다.
- 메시지의 순서는 해당 메시지가 전달되는 시점에 고정된다.
- 주키퍼나 etcd같은 분산 코디네이션 서비스가 이를 구현한다.
- 전체 순서 브로드캐스트는 신뢰성과 순서화 속성이 항상 보장되므로 데이터베이스 복제에 사용하기 적절하다.
# 전체 순서 브로드캐스트로 선형성 저장소 구현
- 전체 순서 브로드캐스트는 신뢰성과 순서화가 되어 있지만 언제 메시지가 전달될지는 모르는 비동기 방식이다. 반면, 선형성은 최신성 보장이 필요하다.
- 전체 순서 브로드캐스트로 선형성 쓰기를 보장할 수 있지만, 선형성 읽기는 보장할 수 없다.
- 쓰기의 경우 들어오는 메시지의 순서화가 보장되기 때문에 유일성 제약 조건을 구현할 수 있다.
- 읽기의 경우 각 노드에 비동기적으로 메시지가 전달되므로 최신 데이터 읽기를 보장할 수 없다.
# 선형성 저장소로 전체 순서 브로드캐스트 구현
- 선형성 저장소가 increment-and-get 연산을 지원하거나 compare-and-set 연산을 지원한다면 모든 메시지에 해당 연산을 통해 일련번호를 붙일 수 있다.
- 일렬번호를 통해 메시지를 순서대로 전달하여 전체 순서 브로드캐스트를 구현할 수 있다.
# 분산 트랜잭션과 합의
합의의 목적은 단지 여러 노드들이 뭔가에 동의하게 만드는 것이다.
노드가 동의하는 것이 중요한 상황은 많이 있다. 대표적으로 리더 선출, 원자적 커밋등이 있다.
# 합의 불가능성
- 어떤 노드가 죽을 가능성이 있다면 합의에 이를 수 있는 알고리즘은 없다는 것을 증명한 FLP 결과가 있다.
- FLP 결과는 어떤 시계나 타임아웃도 사용할 수 없는 결정적인 알고리즘을 가정하는 매우 제한된 모델 기반이다.
- 알고리즘이 타임아웃을 쓸 수 있어 노드가 죽은 것으로 식별할 방법이 있다면 합의는 해결가능해진다.
# 원자적 커밋과 2단계 커밋(2PC)
- 단일 노드에서 트랜잭션의 커밋은 디스크에 쓰여졌는지를 기준으로 쉽게 판단할 수 있다.
- 여러 노드가 트랜잭션에 관여할 때 원자적 커밋을 위해 단지 모든 노드에게 커밋 요청을 보내고 각 노드에서 독립적으로 트랜잭션을 커밋하는건 원자성 보장을 위반할 수 있다.
- 어떤 노드는 충돌로 트랜잭션을 어보트하고, 어떤 노드는 커밋할 수 있음.
- 어떤 노드는 네트워크 결함으로 타임아웃이 발생할 수 있음.
- 어떤 노드는 레코드를 쓰다가 죽어서 복구할 때 롤백되지만, 어떤 노드는 성공적으로 커밋할 수 있음.
- 트랜잭션에 참여하는 노드들은 모든 노드들이 커밋될 것이라고 확실할 때만 커밋이 돼야 한다.
- 사가 패턴처럼 보상 트랜잭션을 통해 커밋을 되돌리는 방식이 있지만 이 방식은 데이터베이스 관점에서는 분리된 트랜잭션으로 애플리케이션의 정확성 요구사항에 따라 불가능 할 수도 있다.
- 사가 패턴에서는 보상 트랜잭션이 나가기 전까지는 클라이언트는 롤백되어야 하는 데이터를 보게된다.
- 2단계 커밋은 모든 노드가 커밋되거나 어보트되도록 보장하는 알고리즘이다.
- 2PC는 코디네이터(트랜잭션 관리자)가 존재하고 애플리케이션이 커밋할 준비가 되면 코디네이터가 1단계를 시작하여 각 노드에 준비 요청을 보내 커밋 가능성을 체크한다.
- 모든 참여자가 커밋할 준비가 됐다고 응답하면 2단계로 커밋 요청을 보낸다.
- 만약, 참여자 중 누구라도 커밋할 준비가 되지 않았다고 하면 2단계에서 모든 노드에 어보트 요청을 보낸다.
- 2PC는 코디네이터(트랜잭션 관리자)가 존재하고 애플리케이션이 커밋할 준비가 되면 코디네이터가 1단계를 시작하여 각 노드에 준비 요청을 보내 커밋 가능성을 체크한다.
# 약속에 관한 시스템
- 2PC는 결국 2단계에서는 각 노드의 상태를 알 수 없기 때문에 1단계 트랜잭션과 다를바가 없어보인다.
- 하지만 2PC에서 코디네이터는 1단계에 각 노드에게 커밋 가능성을 확인한다.
- 각 노드가 코디네이터에게 커밋 가능하다고 응답하는 것으로 각 노드는 트랜잭션을 오류 없이 커밋할 것이라고 약속한다.
- 최종적으로 코디네이터는 모든 노드가 커밋 가능하다고 응답할 때 해당 결과를 기록하고(커밋 포인트) 각 노드에게 전달된다.
- 커밋을 진행하는 경우 노드에서 문제가 발생하더라도 해당 노드는 커밋이 가능하다고 투표했기 때문에 커밋을 거부할 수 없다.
- 2PC 프로토콜은 참여자가 스스로 커밋 가능성을 판단하여 약속하고 코디네이터는 결정하면 그 결정은 변경할 수 없다. 이러한 약속으로 2PC의 원자성을 보장한다.
# 코디네이터 장애
- 코디네이터에 장애가 발생하여 A 노드에겐 커밋 요청을 보냈지만 B 노드에겐 아무런 요청을 보내지 않아 B 노드는 커밋할 지 어보트할 지 알지 못하는 경우가 생길 수 있다.
- 이런 경우 2PC를 완료하기 위해서는 코디네이터가 복구되어 B 노드에게 커밋유무를 알려줄 수 있도록 기다리는 것이 최선이다.
- 이를 위해서 반드시 코디네이터는 합의 결과를 기록해야 한다.
# 내결함성을 지닌 합의
- 합의 알고리즘은 다음 속성을 만족해야 한다.
균일한 동의: 어떤 두 노드 다르게 결정하지 않는다.무결성: 어떤 노드도 두 번 결정하지 않는다.유효성: 한 노드가 값 v를 결정하면 v는 어떤 노드에서 제안된 것이다.종료: 죽지 않은 모든 노드는 최종적으로 어떤 값을 결정한다.
균일한 동의와무결성속성이 합의의 핵심 아이디어를 정의한다. 모두 같은 결과로 결정하며 한 번 결정하면 바뀌지 않는다.종료속성은 내결함성의 아이디어를 형식화한다. 어떤 노드들에 장애가 발생해도 다른 노드는 여전히 결정을 내려야 한다.- 합의 시스템에서 노드가 "죽으면" 그 노드는 다시 돌아오지 않는다고 가정한다. 노드가 복구되기를 기다린다면
종료속성을 만족할 수 없다.
- 합의 시스템에서 노드가 "죽으면" 그 노드는 다시 돌아오지 않는다고 가정한다. 노드가 복구되기를 기다린다면
- 내결함성을 지닌다고 해도 알고리즘이 견딜 수 있는 장애의 수에는 제한이 있다.
- 모든 노드가 죽으면 어떤 알고리즘을 쓰던지 결정은 불가하다. 그러므로 최소한 노드의 과반수가 올바르게 동작해야 한다.
# 합의 알고리즘과 전체 순서 브로드캐스트
- 전체 순서 브로드캐스트는 합의를 여러 번 반복하는 것과 동일하다.
균일한 동의속성 때문에 모든 노드는 같은 메시지를 같은 순서로 전달하도록 결정한다.무결성속성 때문에 메시지는 중복되지 않는다.유효성속성 때문에 메시지는 오염되지 않고 난데없이 조작되지 않는다.종료속성 때문에 메시지는 손실되지 않는다.
# 합의 프로토콜의 투표(에포크 번호 붙이기와 정족수)
- 위에서 설명된 합의 프로토콜은 리더를 사용하지만 리더가 유일하다고 보장하지 않는다.
에포크 번호(epoch, ballot, view, term number)를 정의하고 각 에포크 내에서는 리더가 유일하다고 보장한다.- 에포크 번호는 전체 순서가 있고 리더가 선출될 때 단조 증가된다.
- 현재 리더가 죽었다고 판단될 때 리더 선출을 위해 노드 사이에 투표가 시작된다.
- 만약 그 리더가 죽지 않아 리더 충돌이 발생하면 에포크 번호가 높은 리더가 이긴다.
- 리더는 뭔가를 결정하기 전에 충돌되는 리더가 없는지 확인을 위해
정족수로 부터 투표를 받아야 한다.- 각 노드는 에포크 번호가 더 높은 다른 리더를 알지 못할 때만 제안에 찬성하는 투표를 한다.
- 즉, 두 번의 투표가 존재(
리더를 선출하기 위한 투표,리더의 제안을 결정하기 위한 투표)하며 제안을 결정하는 투표를 하는 노드 중 하나는 반드시가장 최근의 리더 선출 투표에 참여했어서 리더가 올바른지 판단할 수 있어야 한다.
- 합의 알고리즘은 2PC 방식과 다르게 모든 참여자가 아닌 과반수의 투표만을 필요로 하며 이러한 차이점이 합의 알고리즘의 내결함성의 핵심이다.
- 추가로, 새로운 리더가 선출된 후 노드가 일관적인 상태로 만들어주는 복구 과정을 정의해 정확성을 보장할 수 있도록 한다.
# 합의의 제약
- 합의 알고리즘은 분산 시스템에서
안전성 속성(동의, 무결성, 유효성)을 가져오고,내결함성을 유지할 수 있다. 그럼에도 합의 알고리즘은 모든 곳에 쓰이지 않는다.- 노드가 제안에 투표하는 과정은 동기식으로 이루어져야 한다. 이 방식은 성능에 좋지 않다.
- 과반수가 투표를 하기 위해선 노드 한대의 결함을 견디기 위해 최소한 세 대의 노드를 필요로 한다.
- 대부분의 합의 알고리즘은 투표에 참여하는 노드 집합이 고정되어 있다고 가정한다.
- 동적으로 노드 집합이 확장되는 방식의 알고리즘은 훨씬 더 복잡하다.
- 합의 시스템은 장애 노드 감지를 위해 일반적으로 타임에웃에 의존하다.
- 일시적인 네트워크 문제로 인해 노드가 정상 동작하더라도 타임아웃이 발생할 가능성이 충분하다.
- 이 오류가 안전성 속성을 해치지는 않으나 리더 선택에 더 많은 시간을 필요로 하므로 성능에 많은 영향을 준다.
- 신뢰성 없는 네트워크에 더욱 견고한 알고리즘을 설계하는 것은 여전히 해결되지 않은 연구 문제다.
# 멤버십과 코디네이션 서비스
- 주키퍼나 etcd 같은 프로젝트는 종종
분산 키-값 저장소,코디네이션 설정 서비스라고 설명된다. - 주키퍼와 etcd는 메모리 안에 들어올 수 있는 작은 양의 데이터를 보관하도록 설계되었다.
- 이 소량의 데이터는 내결함성을 지는 전체 순서 보로드캐스트 알고리즘을 사용해 모든 노드에 걸쳐 복제된다.
- 이러한 서비스들은 전체 순서 브로드캐스트를 통한 합의 기능뿐만 아니라 분산 시스템을 위한 다양한 기능을 제공한다.
선현성 원자적 연산(잠금): compare-and-set 연산을 사용해 잠금을 구현할 수 있다.연산의 전체 순서화: 연산이 충돌되는 것을 막기 위해 순서화를 제공한다.장애 감지: 주기적으로 health check를 통해 클라이언트의 장애를 감지한다.변경 알림: 알림을 구독하여 클라이언트가 특정 변경에 대해 알 수 있도록 제공한다.
- 주키퍼는 느리게 변하는 데이터 종류를 관리할 때 적절하다. 매초 수천 ~ 수백만 번까지 변경될지도 모르는 애플리케이션에 적절하지 않다.
# 정리
일관성 모델 중 하나인 선형성은 복제된 데이터가 오직 하나의 복사본만 있는 것처럼 보이게 하고 데이터에 대한 모든 연산을 원자적으로 만든다.
- 선형성은 이해하기 쉬우므로 매력적이지만 느리다는 단점이 있다. 특히 네트워크 지연에 더욱 취약하다.
시스템에서 발생한 이벤트에 순서를 부과하는 인과성은 선형성에 비해 더 약한 일관성 모델을 제공한다.
- 선형성은 모든 연산을 하나의
전체 순서로 정할 수 있지만 인과성은 연산에 인과관계가 있는 것들에 대해서부분 순서만 정할 수 있다. - 인과성이 더 약한 일관성 모델을 제공하는 만큼 오버헤드 및 네트워크 지연에 덜 민감하다.
- 하지만, 그 만큼 유일성 보장과 같이 인과성에서 구현할 수 없는 것(유일성 제약)들이 있다. 이 문제는 우리를 합의로 이끈다.
합의를 달성하는 것은 결정된 것에 모든 노드가 동의하고 결정을 되돌릴 수 없는 방식으로 결정하는 것이다.
- 다양한 문제들이 실제로는 합의로 환원될 수 있고 결국 합의의 문제인 것을 알 수 있다.
선형성 compare-and-set 레지스터: 값을 비교하고 설정할지 말지 원자적으로 결정해야 한다.원자적 분산 트랜잭션 커밋: 분산 트랜잭션을 커밋할지 말지 결정해야 한다.전체 순서 브로드캐스트: 메시지를 전달한 순서를 결정해야 한다.잠금과 임차권: 여러 클라이언트들 중 누가 성공적으로 잠금을 획득할지 결정해야 한다.멤버십/코디네이션 서비스: 장애 감지 기준이 정해지면 그 기준을 통해 어떤 노드가 죽었는지 살았는지 결정해야 한다.유일성 제약 조건: 유일성 제약 조건이 위반되어서 실패하도록 할 것인지 결정해야 한다.
- 만약 단일 리더 기반이라면 이러한 문제를 해결하기는 간단하다. 하지만 단일 리더 장애 시 시스템은 아무것도 못하기 때문에 처리 방식을 정해야 한다.
- 리더가 복구될 때까지 기다리고 시스템이 그동안 차단된 것을 받아들인다.
- 이 방법은 리더가 복구되지 않으면 시스템은 영원히 차단된다.
- 운영자가 새 리더 노드를 선택하여 복구한다.
- 운영자의 불가항력에 의해 합의를 도달할 수 있어 많은 RDB가 이 방식을 채택하지만 대처속도가 느리다.
- 자동으로 새 리더를 선택하는 알고리즘을 사용한다.
- 리더가 복구될 때까지 기다리고 시스템이 그동안 차단된 것을 받아들인다.
- 즉, 단일 리더 시스템에서도 위 문제들을 위해 합의가 필요하진 않으나 리더 선출을 위해서 여전히 합의를 필요로 한다.
- 합의로 환원될 수 있는 문제를 해결하고 내결함성을 지니기를 원한다면 주키퍼와 같은 서비스를 사용하는 것이 현명하다.